LXCコンテナの中から、chronydでホストの時刻を補正・配信する
- LXCの標準設定ではセキュリティ上の理由から chrony が動かせないようになっている
- コンテナはホストの時刻を使うため、NTPクライアント(chronyc)は必要はないが、NTPサーバ(chronyd)をコンテナで運用したいことはままある*1
- そこで、セキュリティリスクを承知のうえで、コンテナの中で chronyd を動かして、ホストの時刻を修正したり、時刻を配信したり、できるようにする
検証環境
LXCコンテナ内でのchronyの挙動
とりあえず動かして見る
普通にLXCでコンテナを作った場合、たとえそれが特権コンテナでも chronyd は動作しない。
$ sudo apt install chrony
$ sudo systemctl restart chronyd
$ sudo systemctl status chronyd
● chrony.service - chrony, an NTP client/server
Loaded: loaded (/lib/systemd/system/chrony.service; enabled; vendor preset: enabled)
Active: inactive (dead)
Condition: start condition failed at Wed 2020-11-18 04:18:48 UTC; 2min 14s ago
└─ ConditionCapability=CAP_SYS_TIME was not met
Docs: man:chronyd(8)
man:chronyc(1)
man:chrony.conf(5)
Nov 18 04:18:48 tim systemd[1]: Condition check resulted in chrony, an NTP client/server being skipped.
どうして?
キモになるのはここ。
ConditionCapability=CAP_SYS_TIME was not met
LXCの特権コンテナでは、init が root 権限で実行されている。そのため、何も制限をしないとコンテナの root はホストの root と同等の権限になる*2。
そこでセキュリティ担保のため、コンテナ内の root からは特にセキュリティリスクの高い権限が剥奪されている。CAP_SYS_TIMEはシステムタイマやタイマデバイスを操作するための権限。他にどのような権限があるかは以下の man ページを参照。
自分の環境では、全てのコンテナで共通的に読み込まれる config ファイルで以下のようにいくつかの権限が剥奪されていた。
$ cat /usr/share/lxc/config/common.conf ... # Drop some harmful capabilities lxc.cap.drop = mac_admin mac_override sys_time sys_module sys_rawio ...
lxc.cap.dropは、ここに定義した権限を剥奪するパラメータ。ここで sys_time が設定されているので、CAP_SYS_TIMEが剥奪されている。これが、本事象の原因となる。
対策
上記のパラメータから sys_time を外してしまいたいけども、それをすると全てのコンテナに権限が付与されてしまう。また、困った事にLXCに権限を与えるパラメータはない*3。
仕方がないので、lxc.cap.dropを再定義する。基本的に lxc.cap.drop の設定は重ねがけだが、空欄を指定するとそれまで指定した全ての設定がクリアされるという仕様になっている。
そこで、共有の config は手を付けずに、chronyd を導入したいコンテナの config の一番末尾で空欄指定で一度パラメータをクリアしてから、sys_time を除いた権限を指定する。
$ sudo vim /var/lib/lxc/【コンテナ名】/config ... # Drop some harmful capabilities lxc.cap.drop = lxc.cap.drop = mac_admin mac_override sys_module sys_rawio ...
動作確認
権限を付与するためにコンテナを再起動する。
$ sudo lxc-stop -n 【コンテナ名】 $ sudo lxc-start -n 【コンテナ名】
確認してみる。
$ sudo systemctl status chronyd
● chrony.service - chrony, an NTP client/server
Loaded: loaded (/lib/systemd/system/chrony.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2020-11-18 07:04:41 UTC; 10s ago
Docs: man:chronyd(8)
man:chronyc(1)
man:chrony.conf(5)
Process: 112 ExecStart=/usr/sbin/chronyd $DAEMON_OPTS (code=exited, status=0/SUCCESS)
Process: 124 ExecStartPost=/usr/lib/chrony/chrony-helper update-daemon (code=exited, status=0/SUCCESS)
Main PID: 122 (chronyd)
Tasks: 2 (limit: 4915)
Memory: 1.3M
CGroup: /system.slice/chrony.service
├─122 /usr/sbin/chronyd -F -1
└─123 /usr/sbin/chronyd -F -1
Nov 18 07:04:41 tim systemd[1]: Starting chrony, an NTP client/server...
Nov 18 07:04:41 tim chronyd[122]: chronyd version 3.4 starting (+CMDMON +NTP +REFCLOCK +RTC +PRIVDROP +SCFILTER +SIGND +ASY
NCDNS +SECHASH +IPV6 -DEBUG)
Nov 18 07:04:41 tim chronyd[122]: Initial frequency -10.270 ppm
Nov 18 07:04:41 tim chronyd[122]: Loaded seccomp filter
Nov 18 07:04:41 tim systemd[1]: Started chrony, an NTP client/server.
Nov 18 07:04:47 tim chronyd[122]: Selected source 23.131.160.7
これで、コンテナの中から、ホストのシステムタイマーを制御できるようになる。
余談だが、ホストで既に chronyd や systemd-timesyncd など、タイマを制御するデーモンが動いているなら、止めておかないと大変なことになる。
おわりに
- LXCでは、セキュリティ上の理由から、標準でタイマを制御する権限が剥奪されている
- コンテナ内で chronyd を動かすために、特定のコンテナからタイマを制御する権限を復活させるための手順を整理した
- タイマの制御は、かなりプリミティブな権限なのでくれぐれも自己責任で
systemdで多段プロキシ・リバースプロキシを作る
- systemd だけを使って、多段プロキシやリバースプロキシを作る
- 用途はいろいろあるけど、深く突っ込んじゃイケない
背景
ユースケースはあえて挙げないけど、多段プロキシできるフォワードプロキシとか、一時的なリバースプロキシなど、便利なプロキシサーバが時たま必要になる。
Squidやnginxなどの汎用のものから、Poundやdelegateなどの専用のものまでいろいろな方法があるけども、諸事情*1でこれらが使えない時もある。
そんな時には systemd が使える。systemd は Linux の比較的新しい*2 init システムだが、 init とは思えないほど多機能*3で、実はプロキシサーバが作れてしまう。その手順をまとめる。
検証環境
systemd でプロキシサーバを作る
socket ファイル
まず、リクエストを受け付けるための socket のユニットファイルを用意する。
ListenStreamにリクエストを待ち受けるインタフェースのIPアドレスとポート番号を指定する。
$ sudo vim /etc/systemd/system/proxy.socket [Unit] Description=HTTP Proxy Socket [Socket] ListenStream=0.0.0.0:80
service ファイル
次に、実際にリクエストを経由する service のユニットファイルを用意する。
ExecStartでsystemd-socket-proxydのパスを指定し、第一引数に転送先(多段プロキシなら次のプロキシサーバ、リバースプロキシなら内側のWebサーバ)のIPアドレスとポート番号を指定する。
注意点としては、2つのユニットファイル名はそろえておかないとダメ。(今回は proxy)
$ sudo vim /etc/systemd/system/proxy.service [Unit] Description=HTTP Proxy Service [Service] ExecStart=/usr/lib/systemd/systemd-socket-proxyd 192.168.1.1:5963 PrivateTmp=yes
起動
後はお約束。
systemdをリフレッシュして、
$ sudo systemctl daemon-reload
socketを起動して、
$ sudo systemctl start proxy.socket
うまくいっているようなら、永続化する。
$ sudo systemctl enable proxy.socket
まとめ
- systemd 単体で多段プロキシもしくはリバースプロキシとして使える、プロキシサーバを構築した
ローカルのGitBucketをGitHubに移行する(その3)
- ローカルサーバのGitBucketで管理していたリポジトリをGitHubに移行したい
- 過去記事では、リポジトリの移行と、Issue と Pull Request のダンプを行った
- 今回は、GitBacket からダンプした Issue と Pull Request を GitHub に投稿する
- なお、既に close され branch が消えていた Pull Requset は登録できないので、他のIssueやPull Requestの番号に齟齬が生じないように調整するにとどめる
その1とその2はこちら。
背景
過去記事参照。
GitHub の API
Issue と Pull Request を作って閉じるために必要なAPIは以下の通り。
Issue の投稿
GitHub で Issue を作るときは、 Create an issue の API をコールする。
パラメータは以下の通り。残念ながら、MileStone との対応づけはない。
コール先:POST /repos/:owner/:repo/issues
| パラメータ | 型 | 概要 | GitBucketからダンプしたモノとの対応 |
|---|---|---|---|
| title | string | Issueのタイトル | issue['titile'] |
| body | string | 本文 | issue['body'] |
| milestone | integer | マイルストン番号 | なし |
| labels | array of strings | ラベル名 | issue['labels'][N]['name'] |
| assignees | array of strings | アサイン先 | issue['assignees'][N]['login'] |
Issue へのコメントの投稿
作った Issue にコメントする場合は、 Create an issue comment の API をコールする。
コール先:POST /repos/:owner/:repo/issues/:issue_number/comments
パラメータは以下の通り。issue_comments は、issue の comment_url に格納されているURLから、更にAPIをコールして取得したもの。その2 では、ダンプした issue の中に comments という key を追加して埋め込んでいる。
| パラメータ | 型 | 概要 | GitBucketからダンプしたモノとの対応 |
|---|---|---|---|
| body | string | コメント本文 | issue_comments[N]['body'] |
Issue のクローズ
Issue をクローズする場合は、Update an issue の API をコールする。
コール先:PATCH /repos/:owner/:repo/issues/:issue_number
パラメータは以下の通り。クローズしたいだけなら、state だけ送ればいい。
| パラメータ | 型 | 概要 | GitBucketからダンプしたモノとの対応 |
|---|---|---|---|
| title | string | Issueのタイトル | issue['titile'] |
| body | string | 本文 | issue['body'] |
| milestone | integer | マイルストン番号 | なし |
| labels | array of strings | ラベル名 | issue['labels'][N]['name'] |
| assignees | array of strings | アサイン先 | issue['assignees'][N]['login'] |
| state | string | openかclosed |
issue['state'] |
Pull Request の投稿
Pull Request を作るときは、 Create a pull request の API をコールする。
コール先:POST /repos/:owner/:repo/pulls
パラメータは以下の通り。
| パラメータ | 型 | 概要 | GitBucketからダンプしたモノとの対応 |
|---|---|---|---|
| title | string | タイトル | pull['title'] |
| body | string | 本文 | pull['body'] |
| head | string | 改修後のブランチ名 | pull['head']['ref'] |
| base | string | 改修前のブランチ名 | pull['base']['ref'] |
| draft | boolean | Draft Pull Requestか | pull['draft'] |
Pull Request へのコメントの投稿
Pull Request にコメントを投稿するときは、Issue の時と同様に Create an issue comment の API をコールする。
Pull Request のマージ
Pull Request をマージするときは、 Merge a pull request の API をコールする。
コール先:PUT /repos/:owner/:repo/pulls/:pull_number/merge
パラメータは以下の通り。ただマージしたいだけなら sha だけ合わせておけばいい。
| パラメータ | 型 | 概要 | GitBucketからダンプしたモノとの対応 |
|---|---|---|---|
| commit_title | string | コミットメッセージのタイトル | - |
| commit_message | string | コミットメッセージ | - |
| sha | string | Pull RequestのheadのSHA | pull['head']['sha'] |
| merge_method | string | マージする方法 | - |
Pull Request のクローズ
Pull Request をクローズする場合は、Update a pull request の API をコールする。
コール先:PATCH /repos/:owner/:repo/pulls/:pull_number
パラメータは以下の通り。クローズしたいだけなら、state だけ送ればいい。
| パラメータ | 型 | 概要 | GitBucketからダンプしたモノとの対応 |
|---|---|---|---|
| title | string | タイトル | pull['title'] |
| body | string | 本文 | pull['body'] |
| base | string | 改修前のブランチ名 | pull['base']['ref'] |
| draft | boolean | Draft Pull Requestか | pull['draft'] |
| state | string | openかclosed |
pull['state'] |
手順
これらAPIを用いてGitHubに Issue と Pull Request を移行する。
アクセストークンを発行する
その1で移行したリポジトリに、その2でダンプした Issue を投稿する。
GitHubでもGitBucketの時と同じように、アクセストークンを発行する。
- GitHubにログインする
- アカウントのマイページにアクセスして
- Settings を選択
- Personal access tokens を選択
- Generate new token を選択
- Note にテキトーな名前を入れて
- repo にチェックをして
- Generation Token を選択する
するとアクセストークンが発行されるので、メモしておく。

ダンプした Issue と Pull Request を登録する
注意点は以下の通り。
- Issue 番号 と Pull Request 番号は同じ採番体系になっており、これらは投稿した順に採番される。そのため、元のIssue番号、Pull Request番号の通りに投稿する。
- GitBucket で使っていたユーザ名が、GitHub でも使えるとは限らない。Issue の assignees には GitHub に存在するユーザ名に置換した上で投稿する。
- クローズ済みの Pull Request について、Marge した後、リポジトリから head となる Branch が削除されていたりすると投稿できなくなる。私のリポジトリの場合、クローズ済みの Pull Request にあまり価値はない*1ので、ダミーの Issue を投稿して番号をずらして回避する。
特に工夫点はなく、愚直に API をコールし続ける。その2で作ったコードとマージして完成。
実際のコード
長くなったので、GitHubに公開します。
- ライセンスは The MIT License とします。
結果
- GitBacket 上の Issue と open な Pull Request は Issue 番号やコメントの内容も含めて移行できた。
- クローズした Pull Request はダミーIssue として移行した。
- これで、ローカルのGitBucketのGitHubへの移行は完了となった。
Debian10でGeForce RTX 3080を使ってCUDAするための準備
先日、激戦を勝ち抜き GeForce RTX 3080 を買いました。
ツクモさんで注文し、手に入れることができました!ヒャッホー!!
— kWatanabe (@WWatchin) 2020年10月14日
生まれて初めての単体で6桁円するPCパーツを買いました!!! pic.twitter.com/rlg7Ax45hY
とはいいつつも、私はPCでゲームを殆どしないので、メインマシンは75W級グラボの最高傑作だと思っている Quadro P2200 をそのまま使います。
キター pic.twitter.com/2MN7mjTjoL
— kWatanabe (@WWatchin) 2020年5月2日
では、なぜ GeForce RTX 3080 を調達したかなんですが、自宅のなんちゃって IaaS の GPUコンテナ で CUDA するためです。しかし、GeForce RTX 3080 はリリースされたばかり。debian-backportsでもSidでもドライバが古く、3080 を動かせません。
なので、3080 を動かせるドライバに入れ替えることにしました。
2021/02/03 追記
- 半年の歳月を経て、
buster-backportsにも、GeForce RTX 3080 対応のドライバがリリースされました。現在は、以下の記事に頼らなくても、debian-backportsリポジトリで対応できます。
GeForce RTX 3080 を動かせるLinuxドライバ
GeForce RTX 3080 を使うためには、455.23 以上でなければなりません。2020/10/15現在、Debian の各リポジトリの nvidia-driver のバージョンは以下の通りです。
| リポジトリ | バージョン |
|---|---|
| stable (buster) | 418.152.00-1 |
| backports (buster-backports) | 450.66-1~bpo10+1 |
| testing (bullseye) | 450.66-1 |
| unstable (sid) | 450.66-1 |
不安定版のSidを以てしても、まだ足りません。NVIDIAから公式バイナリを入手する手もあるのですが、できれば apt で一元管理したい。そこで experimental リポジトリを使うことにしました。
experimental リポジトリ
要するに、Sid (不安定版)に取り込む前の開発用リポジトリです。ページには「一般ユーザはこのリポジトリのパッケージを使ってくれるな」(意訳)と書いてあります。
また、各種パッケージのページにも以下の警告が記述されています。
- 警告: このパッケージは experimental ディストリビューションのものです。つまり、おそらく不安定でバグがあり、それどころかデータの損失を起こすかもしれません。使用前には、変更履歴やその他の参照可能なドキュメントを必ず調べてください。
2020/10/15現在、experimental リポジトリの nvidia-driver は455.23です。ちょうど GeForce RTX 3000 をサポートし始めたバージョンです。
導入
手順自体は、debian-backports や Sid を使う時と変わりません。/etc/apt/sources.listにexperimentalリポジトリを追加して、apt するだけです。
$ sudo vim /etc/apt/sources.list deb http://deb.debian.org/debian/ experimental main non-free contrib $ sudo apt update $ sudo apt -t experimental install nvidia-driver
運が良ければ、ちゃんと稼働してくれることでしょう。
2020/11/28 追記
- もし依存パッケージが解決できないようなら
testingやbuster-backportsリポジトリも追加してください。 testingを登録した際、システム全体testingにアップグレードされることを防ぐために/etc/apt/apt.confにAPT::Default-Release "stable";を付けると良いと思います。
2021/01/20 追記
- ついに、
testingに 460 のドライバが降りてきました。 - なので、危ない橋を渡って
experimentalリポジトリを使わなくても、testingリポジトリを足すだけで大丈夫になりました。 - また、今年の夏頃にリリース予定の Debian 11 では、何もしなくても RTX 3080 が使えるようになります。
2021/02/03 追記
- 半年の歳月を経て、
buster-backportsにも、460 のドライバが降りてきました。 - なので、今は Debian10 でも、
buster-backportsリポジトリを足すだけで、RTX 3080 が使えるようになりました。
結果
まだ、GeForce RTX 3080 は組み込んでいませんが、ドライバだけ入れ替えました。GPUをパススルーしたコンテナからも、ちゃんと新しいドライバが動いています。
$ sudo nvidia-smi
Thu Oct 15 00:43:32 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 455.23.04 Driver Version: 455.23.04 CUDA Version: 11.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce GTX 105... On | 00000000:0A:00.0 Off | N/A |
| 29% 31C P8 N/A / 75W | 1MiB / 4040MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
あとは、GeForce RTX 3080 を組み込んで CUDA が動けば問題なしですね。
2020/10/16追記
GeForce RTX 3080 組み込み完了しました。 コンテナの中から、ちゃんと GeForce RTX 3080 を認識できています。バッチリですね。

参考
大元のGPUコンテナを作った時の記事はこちら。 kwatanabe.hatenablog.jp
ローカルのGitBucketをGitHubに移行する(その2)
- ローカルサーバのGitBucketで管理していたリポジトリをGitHubに移行したい
- その1では、リポジトリ本体とユーザ情報、タグなどの移行を行った
- 今回は、データベースで管理されている Issue を GitBacket からダンプする
その1はこちら。
その3はこちら。
背景
過去記事参照。
GitBucket から Issue を取り出す
アプリケーショントークンの取得
GitBucket は GitHub REST API v3 のサブセット*1を実装しているので、直接 H2 や PostgreSQL の中身を覗かなくてもある程度はなんとかなる。
REST API なので python なり perl なりでスクリプトでサクッとおわらせたい。そのためにまずはアプリケーショントークンを取得する。
- GitBucket にログイン
- Account settings を選択
- Applications を選択
- Generate new token の Token description にテキトーな説明を入れる
- Generate token を選択
するとトークンが表示されるのでメモっておく。

Issue と Pull Request の取得
アプリケーショントークンを使って、http://GITBACKET_SERVER_URL/api/v3/repos/USERNAME/REPONAME/issues に対して、APIをコールしてやれば以下のような JSON で降ってくる。
{
'number': 2,
'title': 'Issueのタイトル',
'user': {
'login': 'USERNAME',
'email': 'USERNAME@example.com',
'type': 'User',
'site_admin': True,
'created_at': '2018-08-08T12: 51: 17Z',
'id': 0,
'url': 'http://GITBACKET_SERVER_URL/api/v3/users/USERNAME',
'html_url': 'http://GITBACKET_SERVER_URL/USERNAME',
'avatar_url': 'http://GITBACKET_SERVER_URL/USERNAME/_avatar'
},
'assignee': {
userと同じ key の集まり (valueは異なる)
},
'labels': [
{
'name': 'enhancement',
'color': '84b6eb',
'url': 'http://GITBACKET_SERVER_URL/api/v3/repos/USERNAME/REPONAME/labels/enhancement'
}
],
'state': 'closed',
'created_at': '2018-08-13T14:33:25Z',
'updated_at': '2020-10-10T06:34:36Z',
'body': 'Issueのメッセージ本文',
'id': 0,
'assignees': [
{
user や assignee 同じ key の集まり (valueは異なる)
}
],
'comments_url': 'http://GITBACKET_SERVER_URL/api/v3/repos/USERNAME/REPONAME/issues/2/comments',
'html_url': 'http://GITBACKET_SERVER_URL/USERNAME/REPONAME/issues/2'
}
さらに、Issue 内のコメントは、降ってきた comments_url に対してAPIをコールしてやれば、これまた JSON で手に入る。
[
{
"id": 3,
"user": {
"login": "USERNAME",
"email": "USERNAME@excample.com",
"type": "User",
"site_admin": true,
"created_at": "2018-08-08T12:51:17Z",
"id": 0,
"url": "http://GITBACKET_SERVER_URL/api/v3/users/USERNAME",
"html_url": "http://GITBACKET_SERVER_URL/USERNAME",
"avatar_url": "http://GITBACKET_SERVER_URL/USERNAME/_avatar"
},
"body":"Issueのコメント本文"
}
]
Pull Request と Issue はAPIのエントリポイントが異なるだけで、全く同じ手順でダンプできる。なので、Issue と Pull Request はメソッドを共通化できる。やっつけだが、概ね以下の通り。
【2020/10/20修正】ちょっとやっつけすぎたので、少しリファクタリング。
import os
import requests
GITBUCKET_API_BASEURL='http://gitbucket.example.com/api/v3/repos/USERNAME/REPONAME'
GITBUCKET_APP_TOKEN='XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
# GitBucket から issue を取得する
def get_issues (base_url, token):
headers = {'Authorization': 'token ' + token}
issues = []
# issue
for issue_type in ('issues', 'pulls'):
url = '%s/%s' % (base_url, issue_type)
for state in ('open', 'closed'):
for page in range(1, 10000):
payload = {'state': state, 'page':page}
response = requests.get(url, headers=headers, params=payload)
new_issues = response.json()
if not len(new_issues):
break
issues.extend(new_issues)
issues.sort(key=lambda x: x['number'])
# issue comment
for issue in issues:
response = requests.get(issue['comments_url'], headers=headers)
issue['comments'] = response.json()
return issues
if __name__ == '__main__':
issues = get_issues(GITBUCKET_API_BASEURL, GITBUCKET_APP_TOKEN)
print(issues)
ハマりポイントとしては2点。
- GitBucket の issues API は GitHub では使える state=all が使えないので、state=openとstate=closedを使って結果を結合しないとダメ。
- またper_page=N も使えず、25個ずつしか取ってこれないので、page=N を順繰りに増やし、空配列しか降ってこなくなるまで取得し続けないとダメ。
これで、issue と Pull Request を一通りぶっこ抜けるようになったので、今度はこれを同じく GitHub API を使って GitHub に突っ込んでいく。
次回予告
- GitBucket からぶっこ抜いた Issue と Issue comment を GitHub に入れていきます。
*1:サブセットなので、いろいろと実装が足りなくてハマりポイント多数。ちゃんとしたドキュメントが欲しい
ローカルのGitBucketをGitHubに移行する(その1)
- ローカルサーバのGitBucketで管理していたリポジトリをGitHubに移行したい
- リポジトリ本体は clone して push すれば事が済むが、ユーザ名やメールアドレスが同じとは限らない
- また、データベースで管理されている Issue などはそう簡単にはいかない
- あんまり頑張りすぎずに、できる範囲で移行した際の作業記録(その1)
その2とその3はこちら。
背景
とある事情にて、ローカルのGitBucketをGitHubのプライベートリポジトリに移行することになった
自宅サーバの構成管理をAnsibleでやってるんだけど、Ansible Playbookのリポジトリを自宅サーバのGitBucketで管理しているので、自宅サーバが壊れたらバックアップから引っ張ってこないと再構築できないよな…。
— kWatanabe (@WWatchin) 2020年10月10日
Ansible Playbook だけでも、GitHubのプライベートリポジトリに外出しするか。
GitHub はリポジトリの移行機能を持っていたり、極端な話 clone して push したら済むので、そう難しくない。でも、PostgreSQL に入っている Issue とか、 pull request とかはどうすりゃいいか分からん。
移行ツールとか無いか、いろいろ漁ってみたもののコレといったものが出てこない。なんとかならんものか。
最低限守りたいモノ
とりあえず、あんまり頑張りたくないので、最低限守りたいものを整理する。
プルリクは、たまたまオープンのものが無かったので、特に意識はしていない。
【2020/10/11訂正】 Issue だけだと、Issue 番号がずれてしまうので、プルリクも入れてやらないとダメだった。
リポジトリ
フルミラーの取得
リポジトリの完全なミラーを取得する。
まずは単純に clone して。
$ git clone <リポジトリのURL>
ブランチを確認して。
$ cd <cloneしたディレクトリ> $ git branch -r | grep -v "\->" | grep -v master origin/issue103
見つけたブランチも引っ張ってくる。
$ git branch --track issue103 origin/issue103 $ git branch issue103 * master
多分大丈夫だと思うけど、fetch と pull もしておく。
$ git fetch --all $ git pull --all
おっけー。
ユーザ情報を GitHub のものに移行
ユーザ情報(AuthorとCommitter)が、ローカルとGitHubアカウントで齟齬があるので、コレを修正する。
齟齬とはいったものの、実態としてローカルのリポジトリでは、好き勝手にでっち上げたユーザ名とメールアドレスを使ってコミットしていたのでもうグチャグチャ。まずは、こいつを GitHub のそれに合わせて整える。
現状を確認する。
$ git log --pretty=full …(略)… Author: XXXX <XXXX@XXXX.com> Commit: XXXX <XXXX@XXXX.com> …(略)…
もし、GitHubのユーザ名が kwatanabe、 メールアドレスが kwatanabe@example.com だとすると、こうする。
$ git filter-branch -f --env-filter "GIT_AUTHOR_NAME='kwatanabe'; GIT_AUTHOR_EMAIL='kwatanabe@example.com'; GIT_COMMITTER_NAME='kwatanabe'; GIT_COMMITTER_EMAIL='kwatanabe@example.com';" HEAD Ref 'refs/heads/master' was rewritten
もし、ブランチがあるならそれぞれで同じ事をやっておく。
$ git checkout BRANCH Switched to branch 'BRANCH' Your branch is up to date with 'origin/BRANCH'. $ git filter-branch -f … (省略)
修正されたことを確認。
$ git log --pretty=full …(略)… Author: kwatanabe <kwatanabe@example.com> Commit: kwatanabe <kwatanabe@example.com> …(略)…
試しに push してみる
とりあえずこれでリポジトリは整った。試しにGitHubにプッシュしてみる。
GitHubでプラベートリポジトリを作る。このとき、「Add a README file」と「Add .gitignore」のチェックを外しておく。

リポジトリのPUSH先URLを変更する。
$ git remote set-url origin https://github.com/<ユーザ名>/<リポジトリ>
あと、GitHubのデフォルトブランチ名は master ではなく main に変わった*1ので、メインブランチ名を変更する。
$ git branch -M main $ git branch issue103 * main
PUSHする。
$ git push --all origin $ git push --tags
GitHubのコンソールに入って、リポジトリのブランチとタグがきちんと反映されてることを確認しておく。

あと、きちんとコミットとユーザが紐付き、いわゆる"草原"に反映されていることを確認する。

次回予告
単なるリポジトリの移行だけであれば、コレで完了。
Issue やら Release やらをコピーしたい場合は、GitBucket から どうにかしてぶっこ抜く必要がある。
これは以下の記事参照です。
LXCの非特権コンテナにホストのGPUをパススルーする
- 2020/11/08 一部のtypoを修正
大要
- Proxmox VEのLXCの非特権コンテナにGPUをパススルーし、CUDAを使う
- KVMのVGAパススルーと違って、ホストに搭載するGPUは1つでよい
- GPUは(性能を考慮しないなら)そのままホストでも利用できる
- (たぶん、)生のLXCでも同等の手順で実現できる
背景
- 我が家では Ryzen マシンに Proxmox VE を入れて、IaaS モドキを運用している(以前は CloudStack + XenServer だったが、XenServer 無料版 の制限強化の際にやめた)
- Ryzen はGPUを持たないので、コンソール用に GeForce GTX 1050Ti を挿しているが、非常時以外は使わないので勿体ない
- LXCの非特権コンテナ上で 1050Ti を使って CUDA ができれば、追加費用なしで手軽にGPUインスタンスが手に入るのではと思った
ターゲット環境
- LXCホスト:Proxmox VE 6.2 (サブスクリプションなし)
- LXCゲスト:Debian 10.6 (非特権コンテナ)
- GPU:Geforce GTX 1050Ti
手順
大まかな手順は以下の通り。
- ホストでGPUのドライバをビルド
- ホストでGPUのデバイスファイルを有効化
- ゲストにGPUのデバイスファイルをリマップ
- ゲストでGPUのドライバをビルド
- ゲストでCUDAのライブラリをインストール(割愛)
ホストでGPUドライバをビルド
サブスクリプションを持たない人向けの Proxmox リポジトリを有効にする。もちろん、サブスクリプションをお持ちの場合は不要。
# vim /etc/apt/sources.list deb http://download.proxmox.com/debian/pve buster pve-no-subscription
Proxmox VE のリポジトリには nvidia-driver がないので、Proxmox VE 6.x のベースである Debian 10 のリポジトリを有効にする。なお、stable リポジトリの nvidia-driver は古いので、backports リポジトリを用いる。
# vim /etc/apt/sources.list deb http://deb.debian.org/debian buster-backports main contrib non-free deb-src http://deb.debian.org/debian buster-backports main contrib non-free
nvidia-driver を導入する。nvidia-driver はバイナリで提供されていないので、DKMS*1 でその場でビルドされる。そのため、カーネルヘッダやビルドツールも一式必要になる。
# apt update # apt upgrade # apt install pve-headers build-essentials # apt install -t buster-backports nvidia-driver nvidia-smi
ホストでGPUデバイスファイルを有効化
DKMSでビルドされたドライバモジュールを有効にする。
# vim /etc/modules-load.d/nvidia-gpu.conf nvidia-drm nvidia nvidia_uvm
udevルールを作成して、ドライバがロードされた時に非特権コンテナからでもデバイスファイルを扱えるように、アクセス権が変更されるようにする。(特権コンテナの場合は不要)
余談だが、非特権コンテナから扱えるようにアクセス権を緩めると、ホストの一般ユーザ(Proxmox VEに一般ユーザはないが)からでもデバイスファイルが叩けるようになってしまう。でも、コンテナを特権コンテナにするよりはまだマシか…?
# vim /etc/udev/rules.d/70-nvidia-gpu.rules KERNEL=="nvidia", RUN+="/bin/bash -c '/usr/bin/nvidia-smi -L && /bin/chmod 666 /dev/nvidia*'" KERNEL=="nvidia_uvm", RUN+="/bin/bash -c '/usr/bin/nvidia-modprobe -c0 -u && /bin/chmod 0666 /dev/nvidia-uvm*'"
ホストを一度再起動する。
# reboot
起動したら、GPUが正しくホストで認識されているか確認する。
# nvidia-smi
Sun Oct 4 15:42:59 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.100 Driver Version: 440.100 CUDA Version: N/A |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 105... On | 00000000:0A:00.0 Off | N/A |
| 29% 29C P8 N/A / 75W | 1MiB / 4040MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
ゲストにGPUデバイスファイルをリマップ
コンテナの設定ファイルを開いて、GPUのデバイスファイルをリマップする。
例えば、対象のコンテナの vmid が 101 だった場合は、以下の通り。
# vim /etc/pve/lxc/101.conf lxc.cgroup.devices.allow: c 195:* rwm lxc.cgroup.devices.allow: c 236:* rwm lxc.cgroup.devices.allow: c 226:* rwm lxc.mount.entry: /dev/nvidia0 dev/nvidia0 none bind,optional,create=file lxc.mount.entry: /dev/nvidiactl dev/nvidiactl none bind,optional,create=file lxc.mount.entry: /dev/nvidia-uvm dev/nvidia-uvm none bind,optional,create=file lxc.mount.entry: /dev/nvidia-modeset dev/nvidia-modeset none bind,optional,create=file lxc.mount.entry: /dev/nvidia-uvm-tools dev/nvidia-uvm-tools none bind,optional,create=file lxc.mount.entry: /dev/dri dev/dri none bind,optional,create=dir
コンテナを起動して、コンテナの中からもデバイスファイルが見えている事を確認する。
$ ls /dev/nvidia* /dev/dri/* /dev/nvidia0 /dev/nvidiactl /dev/nvidia-modeset /dev/nvidia-uvm /dev/nvidia-uvm-tools /dev/dri/card0 …(省略)…
ゲストでGPUドライバをビルド
ホストと同様にコンテナでGPUのドライバをビルドする。今回は Proxmox VE のベースである Debian 10 のコンテナなので、カーネルヘッダが異なる以外は同じ。
まずは、backports リポジトリを有効にして…。
$ sudo vim /etc/apt/sources.list deb http://deb.debian.org/debian buster-backports main contrib non-free deb-src http://deb.debian.org/debian buster-backports main contrib non-free
次に、DKMS でドライバをビルドする。
$ sudo apt update $ sudo apt upgrade $ sudo apt install build-essential $ sudo apt install -t buster-backports nvidia-driver nvidia-smi
コンテナの内部からGPUにアクセスできるか確認する。
$ nvidia-smi …(省略)…
あとは、実機でCUDAを使うときと同様に、コンテナにCUDAドライバをインストールする。ここでは割愛する。
備考
- ホストとゲストのドライバは同じバージョンが望ましい。
- Debian 10 以外のコンテナにパススルーする場合は、ディストリビューションのドライバのバージョンを確認して、少しでも違ったら公式ドライバでバージョン合わせをするのが無難
- Proxmox VE 固有の手順は殆どないので、多分、生のLXCでも同じ手順で使えると思う
まとめ
AWS・Azure・自宅にてマルチでハイブリッドなクラウドを作ってみた(その2)
大要
- 自学自習のため、マルチでハイブリッドなクラウドを作ってみた
- ゴールは、各リソースをパブリックな通信なしで利用できるようにすること
- 前回はL3レベルでのサイト間VPNで、IaaS層のハイブリッド化行った
- 今回は AWS と Azure の PaaS を各拠点のネットワークで相互に繋いで PaaS層のハイブリッド化を行う
前回はこちら kwatanabe.hatenablog.jp
背景
- 前回記事参照
PaaSのハイブリッド化
- 前回の作業でAmazon VPC、Azure VNet、自宅のLANが相互に接続されている
- PaaSをこれらVPCやVNetに所属させることができれば、PaaSのハイブリッド化も実現できる
- Azure PaaS と AWS PaaS では設計思想の違いから必要なアプローチが異なる
AWS PaaS
- AWS PaaS は VPC に対してプラガブルな設計となっているので、多くのメニューでそのまま VPC のサブネットに繋げることができる
- 例えば、Amazon RDS だと作成時にVPCとサブネットグループを指定できる
- RDSのマルチAZ対応するには適切なルーティング設定が VPC に必要

Azure PaaS
- VNet は IaaS のための仕組みであり、PaaS の接続は考慮されていない
- Azure PaaS は各リソースがパブリックな世界で孤立している
- VNet に繋ぐには、そのための機能が PaaS に備わっている必要がある
- 例えば、Azure App Service では以下の機能が提供されている
docs.microsoft.com docs.microsoft.com docs.microsoft.com
具体例

- Azure App Service と Amazon RDS を繋いで簡単なWebシステムを作る
- RDS のパブリックアクセシビリティを無効にして、マルチクラウドが実現できている事を確認する
- App Serivce を VNet に接続する手段は Region VNet Integration を用いる
Amazon RDS
インスタンスを作成する。作成に特別な手順は必要ない。以下のパラメータ以外は好きに選んでかまわない。
- エンジン:MySQL (MySQL Community 8.0.20)
- マルチAZ配置:なし
- 接続VPC:Hybrid-VPC (前回記事参照)
- サブネットグループ:新規
- パブリックアクセス:なし
- VPCセキュリティグループ:3306/TCPを許可
- アベイラビリティゾーン:Hybird-Subnetと同じところ
- データベースポート:3306
- 認証:パスワード認証
- 最初のデータベース名:wordpress
インスタンスがデプロイされたら、コンソールからエンドポイント名を確認したうえで、同じサブネットに属するEC2からプライベートIPアドレスを調べておく。

$ nslookup XXXXXXXXXXXXXXXXXXXXX.ap-northeast-1.rds.amazonaws.com Server: 192.168.20.2 Address: 192.168.20.2#53 Non-authoritative answer: Name: XXXXXXXXXXXXXXXXXXXXX.ap-northeast-1.rds.amazonaws.com Address: 192.168.20.225
以上でRDSの構築は完了。
Azure App Service
インスタンスを作成する。まずは通常の手順でデプロイする。
- 公開:コード
- ランタイムスタック:PHP 7.3
- オペレーティングシステム:Linux
- 地域:Japan East
- Linuxプラン:(新規)
- SKUとサイズ:S1
ネットワーク⇒VNet統合から、以下の設定を行う。
- 仮想ネットワーク:前回作成した Azure VNet
- サブネット:Hybrid_Subnet_Dammy
構成⇒アプリケーションの設定から、以下の設定を行う。
- パラメータ:WEBSITE_VNET_ROUTE_ALL
- 値:1
デプロイセンター⇒FTPから接続情報を取得して、FTPクライアントで任意のディレクトリに Wordpress のアーカイブを展開する。
- なお、5.5系はPHP7.4以降を推奨としているため、5.4系を用いる
一旦、App Serivceを「停止」⇒「起動」でコールドブートした後に、WordPress をデプロイした URL にブラウザで繋ぎ、初期設定を行う。
- データーベースのホスト名は、RDS をデプロイしたときに調べたプライベートIPアドレスを指定する。

以上でApp Serivceの構築は完了。
まとめ

AWS・Azure・自宅にてマルチでハイブリッドなクラウドを作ってみた(その1)
大要
- 自学自習のため、マルチでハイブリッドなクラウドを作ってみた
- AWS、Azure、自宅の各拠点をプライベートなネットワークで結ぶ
- ゴールは、各リソースをパブリックな通信なしで利用できるようにすること
- まずは、Softether VPNでサイト間VPNを構築した
次回は PaaS を VPN に繋げる話。 kwatanabe.hatenablog.jp
背景
- 浦島太郎なkWatanabeにとって、クラウドといえばOpenNebula、OpenStack、CloudStackであって、パブリックなクラウドは馴染みがない
- コレはイカんと思い、会社の勉強会*1にかこつけて、何かパブリッククラウドで遊んでみようと思った
- システムを知るにはまずは足回りからがモットーなので、まずは生の計算機とネットワークが見えそうな、マルチでハイブリッドなクラウドに挑戦した
マルチでハイブリッドなクラウド

サイト間VPN

- まず、各拠点をプライベートなネットワークで結ぶためにサイト間VPNを作る
- 各事業者でVPNのPaaSを提供
- 今回は1つの仕組みで完結させる為、Softether VPNを採用
- 注意点としては、AWSもAzureも仮想ネットワークはL3レベルでフィルタされているので、L2ではなくL3でサイト間VPNをはる必要がある
ネットワークの整備
自宅
- 192.168.1.0/24 が整備されている
- VPNサーバ以外の各端末のルーティングテーブルを設定する
- 192.168.20.0/24 via 192.168.1.249 (VPNサーバの仮想L3スイッチの内向きアドレス)
- 192.168.21.0/24 via 192.168.1.249 (同上)
- 192.168.30.0/24 via 192.168.1.249 (同上)
- 192.168.31.0/24 via 192.168.1.249 (同上)
- 192.168.10.0/24 via 192.168.1.249 (同上)
Amazon VPC
- CIDRの範囲:192.168.20.0/24 と 192.168.21.0/24
- サブネット「Hybrid-Subnet」
- サブネット「Hybrid-Subnet-Dammy」
- CIDR:192.168.21.0/24
- アベイラビリティゾーン:Hybrid-Subnetと異なるところ
- ルートテーブルなし
Azure VNet
- IPv4 アドレス空間:192.168.30.0/24 と 192.168.31.0/24
- サブネット「Hybrid_Subnet」
- CIDR:192.168.30.0/24
- ルートテーブル
- 192.168.1.0/24 via 192.168.30.100 (VPNブリッジのVirtualMachine)
- 192.168.20.0/24 via 192.168.30.100 (同上)
- 192.168.21.0/24 via 192.168.30.100 (同上)
- サブネット「Hybrid_Subnet_Dammy」
- CIDR:192.168.31.0/24
- ルートテーブルはHybrid_Subnetと同じ
- BastionHost:無効化
- DDoS Protection Standard:無効化
- ファイアウォール:無効化
- サブネット「Hybrid_Subnet」
Softether VPN のインストール
自宅(VPNサーバ)
- 環境は、LXCで構築した Debian 10 のシステムコンテナ
- ネットワークインタフェースは2つ
SoftEther の サイトから Linux 64bit 用のバイナリを入手してリンクする
$ sudo apt install wget gcc make $ cd /opt $ wget https://jp.softether-download.com/files/softether/v4.34-9745-rtm-2020.04.05-tree/Linux/SoftEther_VPN_Server/64bit_-_Intel_x64_or_AMD64/softether-vpnserver-v4.34-9745-rtm-2020.04.05-linux-x64-64bit.tar.gz -O - | sudo tar xzf - $ cd /opt/vpnserver $ sudo make
systemdのユニットファイルを作成して、自動起動を有効化する
$ cat << EOF | sudo tee /etc/systemd/system/softether-vpnserver.service [Unit] Description=Softether VPN Server Service After=network.target [Service] Type=forking User=root ExecStart=/opt/vpnserver/vpnserver start ExecStop=/opt/vpnserver/vpnserver stop Restart=on-abort WorkingDirectory=/opt/vpnserver [Install] WantedBy=multi-user.target EOF $ sudo chmod +x /etc/systemd/system/softether-vpnserver.service $ sudo systemctl daemon-reload $ sudo systemctl start softether-vpnserver $ sudo systemctl enable softether-vpnserver
適当な端末から eth0 に向かって、SoftEther VPN Managerで接続して、以下の設定を施す。
- 仮想HUB「DEFAULT」の設定
- ユーザ名:テキトー
- 認証方法:パスワード認証
- SecureNATは無効
- ローカルブリッジ:eth1
- 仮想HUB「HYBRID」の設定
- ユーザ名:テキトー
- 認証方法:パスワード認証
- SecureNATは無効
- 待受ポート:5555/TCP (SE-VPN) のみ
- 仮想L3スイッチの設定
- インターフェース
- 192.168.1.249 ⇒ 接続先HUB「DEFAULT」に接続
- 192.168.10.1 ⇒ 接続先HUB「HYBRID」に接続
- ルーティングテーブル
- 192.168.20.0 ⇒ 192.168.10.2 (AWS用)
- 192.168.30.0 ⇒ 192.168.10.3 (Azure用その1)
- 192.168.31.0 ⇒ 192.168.10.3 (Azure用その2)
- インターフェース
以上で設定完了。
AWS および Azure(VPNブリッジ)
- Amazon EC2 と Azure VirtualMachine で Debian10 のインスタンスを作成
SoftEther の サイトから Linux 64bit 用のバイナリを入手してリンクする。
$ sudo apt install wget gcc make $ cd /opt $ wget https://jp.softether-download.com/files/softether/v4.34-9745-rtm-2020.04.05-tree/Linux/SoftEther_VPN_Bridge/64bit_-_Intel_x64_or_AMD64/softether-vpnbridge-v4.34-9745-rtm-2020.04.05-linux-x64-64bit.tar.gz -O - | sudo tar xzf - $ cd /opt/vpnbridge $ sudo make
ユニットファイルを作成して、自動起動を有効化する
$ cat << EOF | sudo tee /etc/systemd/system/softether-vpnbridge.service [Unit] Description=Softether VPN Bridge Service After=network.target [Service] Type=forking User=root ExecStart=/opt/vpnbridge/vpnbridge start ExecStop=/opt/vpnbridge/vpnbridge stop Restart=on-abort WorkingDirectory=/opt/vpnbridge [Install] WantedBy=multi-user.target EOF $ sudo systemctl daemon-reload $ sudo systemctl start softether-vpnbridge $ sudo systemctl enable softether-vpnbridge
VPNブリッジは自力でアドレス変換しないとダメなのでポートフォワードを有効化
$ sudo vim /etc/sysctl.conf net.ipv4.ip_forward = 1 $ sudo sysctl -p
適当な端末から、SoftEther VPN Managerで接続して、以下の設定を施す。
- 仮想HUB「BRIDGE」
SoftEther VPN の設定後に、tapデバイスに ip addr でIPアドレスを設定
- AWS:192.168.10.2
- Azure:192.168.10.3
SoftEther VPNの設定後に、ip route でローカルのルーティングテーブルを編集
- AWS
- 192.168.1.0/24 via 192.168.10.1 dev tap_vpntap
- 192.168.30.0/24 via 192.168.10.1 dev tap_vpntap
- 192.168.31.0/24 via 192.168.10.1 dev tap_vpntap
- Azure
- 192.168.1.0/24 via 192.168.10.1 dev tap_vpntap
- 192.168.20.0/24 via 192.168.10.1 dev tap_vpntap
改めて、SoftEther VPN Managerで接続して、以下の設定を施す。
- 仮想HUB「BRIDGE」
- カスケード接続:仮想HUB「HYBRID」
- 状態:オンライン
- カスケード接続:仮想HUB「HYBRID」
以上で設定は完了。
まとめ
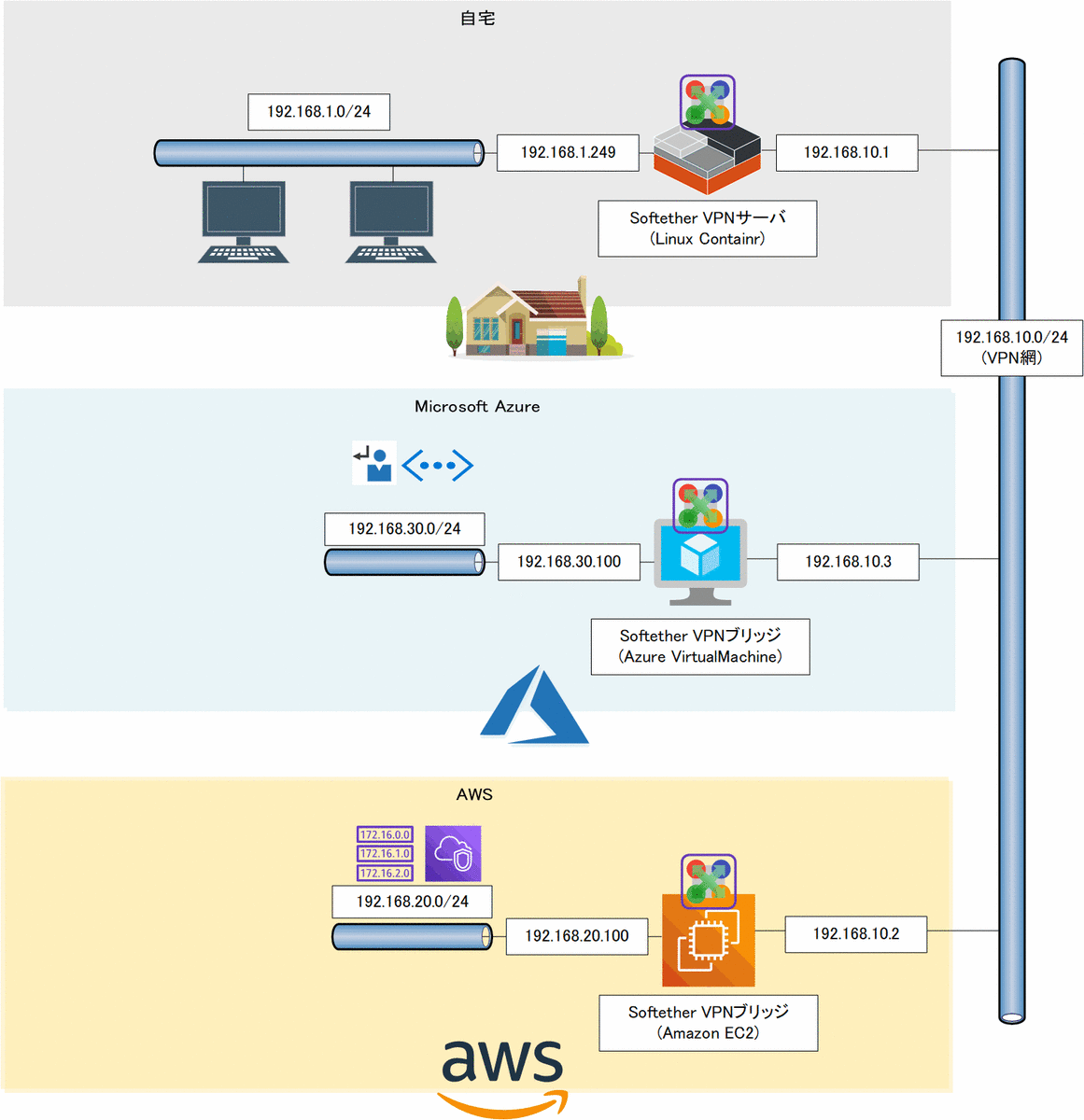
- 本記事の手順を実施した時点で上記の環境が構築できている
- IaaS レベルのハイブリッドクラウドであれば、これで構築完了
- 各拠点間の端末から ping を送りあうと疎通ができるはず
- 次回は各拠点に PaaS をデプロイして、疎通できるようにする
次回に続く kwatanabe.hatenablog.jp
クラウド課金で死なないための予算管理
大要
- パブリッククラウドは使った分だけ課金される
- リソース解放漏れにより、思わぬ請求が来ることを防止したい
- 予算に基づいたアラートを設定した
- 思わぬ課金に気づけるようになった
パブリッククラウドは使えば使うだけ課金される
浦島太郎なkWatanabeは、計算機リソースに対する課金といえばリース代や電気代、あるいはVPSなどの固定額モデルしか馴染みがない。
これらは無茶な使い方をしても、性能が出ない・機能が足らないなど、クールダウンできるタイミングがあったけど、パブリッククラウドではそうはいかない。 リソースは足りなければ足されるし、請求額も膨れていく。
自制できずに課金されるなら自業自得だが、解放漏れによる課金はいただけない。
予算を管理する
リソースを監視する仕組みを入れてもいいけども、個別に対応して漏れると本末転倒なので、まずは水際対策として課金状況に応じたアラートを設定する。
Microsoft Azure の場合
Azure Portalの「サブスクリプション」>「予算」から、予算額とアラートを出す閾値を設定できる。
スコープはサブスクリプションでもいいし、リソースグループでもいい。 解放漏れなどイレギュラーな課金への対策はサブスクリプションに設定して、実際の予算はリソースグループにしておくと、管理が楽かもしれない。

使ったつもりもないのに課金されている場合に備えて1000円。自己牽制として4000円。 額は、とりあえず適当に入れた。これで閾値をまたいだ際に、約1時間以内にアラートが届くようになるらしい。
AWSの場合
AWS Management Consoleの「マイアカウント」>「Budgets」から、予算額とアラートを出す閾値を設定できる。
AWSの場合、課金単位は全てUSDなので、予算もUSDで指定する。 これは、請求額をJPYにしても同じ。
アラートを出す閾値は「実際に掛かった額」または「予測額」で設定できるので、組み合わせて使えばリソースの解放漏れを事前に察知できるかもしれない。

こちらも、同様に使ったつもりが無い場合と自己牽制のために2つのアラートを設定。額はとりあえず適当に入れた。
まとめ
はじめまして kWatanabeです
意気込み
はじめまして。kWatanaeです。
2010年頃には、iTRONやRT-Linux、Xen、KVM などを活用したリアルタイムシステムの研究。
2015年頃には、OpenStack、CloudStack などのプライベートクラウド や Pacemaker、ZooKeeper、ZeroMQ などを活用したHAクラスタの開発をやってました。
その後、炎上プロジェクトにドナドナされ、2020年頃に戻ってきたのはいいものの、世の中はパブリッククラウド一色。それもPaaS/SaaS/FaaSの全盛期。
浦島太郎からイマドキのエンジニアなるため、頑張ります。
これから
パグリッククラウド一色の世の中とはいえ、誰かはオンプレやネットワークもちゃんと見ないといけません。オンプレとクラウドのコラボレーションをテーマとして、Low-Level も High-Level も何でもキャッチアップしていきます。
今後ともよしなに。