修理交換に備えて、LinuxサーバのHDDを暗号化する
本記事は暗号化やセキュリティに関する記述がありますが、個人のメモ書きであり、内容の正しさを含め、直接的・間接的を問わず生じた問題等に対して、著者は一切の責任を負いません。
概要
- 保証期間内にHDDが故障した際、修理交換のためにHDDを送付したいが、中のデータを削除できずに送付できないジレンマがある
- HDDが故障する前に透過的暗号を導入しておくことで、HDDからのデータ流出を防止する
自宅サーバのHDDが壊れた
我が家のサーバは、NASやエンタープライズ向けのHDDを利用しており、保証期間が数年と長く設定されているが、今回は残念ながら期限が切れていた。無念。
バックアップサーバの調子の悪いHDD。NAS向け製品で保証期間が長いので、ワンチャンあるかと思ったが、2022年末で切れていた。残念。 https://t.co/Mxeo6qwqaF
— kWatanabe (@WWatchin) 2024年1月2日
一方、保証期間内であったとしても、データを含むHDDをメーカーに送ることは中々難しい。
故障品だとしても、検査の際にたまたま動くこともあるだろうし、メーカーならば故障部品を交換すればサルベージも簡単だと考えられる。廃棄時のように物理破壊するわけにもいかないし、故障しているので上書き消去もできない。
透過的暗号による保護
このような背景から、故障する前に他人からデータを読み取れない状態にしたい。その一方で、故障するまでは特別な操作なしに扱えるようにしたい。
これを実現するために透過的暗号を導入する。透過的暗号は、アクセスの際に自動で暗号と復号を行う仕組みで、鍵を持つ者は通常のHDDと同様に扱えるが、鍵を持たない者はデータが読み取れない。故障時はHDDのみを提出することで、物理アクセスによる情報流出の防止に期待する。
dm-crypt + LUKS
Linux の透過的暗号の仕組みとしては、dm-crypt と LUKS の組み合わせが主流らしい。
ディスク単体の暗号化から、システム全体の暗号化、複数の鍵を用いたアクセス制御や、ネットワークを用いた鍵配信まで、かなり高度な構成が取れる模様。
想定する驚異モデル
設定を検討するうえで、故障したHDDをメーカー修理に出すユースケースを想定し、驚異モデルを以下の通りとする。
- 攻撃者は、機密情報が含まれるHDD本体を入手できる
- 攻撃者は、入手したHDD本体へのあらゆる物理的アクセスができる
- 攻撃者は、HDDが搭載されていたサーバやその他のデバイスにはアクセスできない
- 内部犯・外部犯による攻撃や盗難は考慮しない。
すなわち、以下の設定では情報システムとしてのセキュリティ対策にはならない点に注意。
検証
パッケージの導入とアルゴリズムの選定
基本的な機能はカーネルが提供するため、導入するパッケージは管理ツールのみ。
$ sudo apt install cryptsetup
暗号化に用いるアルゴリズムを選定するため、ベンチマークを行う。
$ sudo cryptsetup benchmark # テストはストレージI/Oがなくメモリ上のもののため目安です。 PBKDF2-sha1 2396745 回/秒 (256 ビットの鍵) PBKDF2-sha256 4319571 回/秒 (256 ビットの鍵) PBKDF2-sha512 1829975 回/秒 (256 ビットの鍵) PBKDF2-ripemd160 1071068 回/秒 (256 ビットの鍵) PBKDF2-whirlpool 799219 回/秒 (256 ビットの鍵) argon2i 6 回, 1048576 KB使用, 4 スレッド (256 のビットの鍵) (2000 ms 計測) argon2id 6 回, 1048576 KB使用, 4 スレッド (256 のビットの鍵) (2000 ms 計測) # Algorithm | キー | 暗号化 | 復号化 aes-cbc 128b 1768.2 MiB/s 6683.9 MiB/s serpent-cbc 128b 118.3 MiB/s 816.0 MiB/s twofish-cbc 128b 261.4 MiB/s 526.6 MiB/s aes-cbc 256b 1415.0 MiB/s 5387.8 MiB/s serpent-cbc 256b 125.2 MiB/s 815.0 MiB/s twofish-cbc 256b 297.4 MiB/s 527.2 MiB/s aes-xts 256b 5489.9 MiB/s 5485.2 MiB/s serpent-xts 256b 779.2 MiB/s 740.5 MiB/s twofish-xts 256b 488.7 MiB/s 498.9 MiB/s aes-xts 512b 4897.4 MiB/s 4866.2 MiB/s serpent-xts 512b 786.7 MiB/s 740.2 MiB/s twofish-xts 512b 492.0 MiB/s 499.0 MiB/s
このシステムでは、ハッシュ化アルゴリズムは sha256、暗号化アルゴリズムは aes-xts が最も高速であることが分かる*1。256bitのAESならば強度の面でも申し分ない*2。
暗号化ボリュームの作成
今回は、/dev/sdb にパーティションを作成し、暗号化ボリュームとする。パーティションの作成に特別な手順は必要ない。
$ sudo fdisk /dev/sdb Command (m for help): g Command (m for help): n Partition number (1-128, default 1): First sector (2048-16777182, default 2048): Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-16777182, default 16775167): Command (m for help): w
ベンチマークの結果を参考に、暗号化ボリュームを初期化する。今回は、(故障するかもしれない)HDD以外にはアクセスされない前提のため、アンロックするための鍵は、別のディスクにキーファイルを作成し、これを用いる。
まず、キーファイルを作成する。
$ sudo mkdir -p /etc/luks-keyfile
$ cat /dev/urandom | tr -dc "[:graph:]" | fold -w 2048| head -n 1 | sudo tee /etc/luks-keyfile/test ...
一応、root 以外で閲覧できないようパーミッションを設定する。
$ sudo chmod 700 /etc/luks-keyfile
$ sudo chmod 400 /etc/luks-keyfile/test
暗号化ボリュームを作成する。
$ sudo cryptsetup -v --cipher aes-xts-plain64 --key-size 256 --hash sha256 luksFormat /dev/sdb1 /etc/luks-keyfile/test 警告!! ======== /dev/sdb1 のデータを上書きします。戻せません。 よろしいですか? ('yes' を大文字で入力してください): YES キースロット 0 が作成されました。 コマンド成功。
手動でのアンロック
作成した暗号化ボリュームをアンロックし、 /dev/mapper/crypt-sdb1 としてマップする。
$ sudo cryptsetup open --type luks --key-file /etc/luks-keyfile/test /dev/sdb1 crypt-sdb1
すると、以下のように透過的暗号のレイヤが挿入される。
$ sudo lsblk -p /dev/sdb NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS /dev/sdb 8:16 0 8G 0 disk └─/dev/sdb1 8:17 0 8G 0 part └─/dev/mapper/crypt-sdb1 254:0 0 8G 0 crypt
以降は、このレイヤを物理HDDと同じように扱うことで、透過的暗号が実現される。
$ sudo mkfs -t ext4 /dev/mapper/crypt-sdb1
$ sudo mount /dev/mapper/crypt-sdb1 /mnt
$ ls /mnt
lost+found/
自動でのアンロック
今回は、利用中の盗難や攻撃を想定しないため、システムが起動すると自動でアンロックされ、ファイルシステムとしてマウントできるようにする。
そのために、まず暗号化ボリュームのUUIDを調べる。
$ sudo blkid /dev/sdb1 /dev/sdb1: UUID="e8e54b6a-6312-456b-bdff-5c7762b69d01" TYPE="crypto_LUKS" PARTUUID="30a698c2-c227-7f4c-8239-164128126283"
調べたUUID、マップするデバイスファイル、アンロックのためのキーファイルを /etc/crypttab に記述する。
$ sudo vi /etc/crypttab crypt-sdb1 UUID=e8e54b6a-6312-456b-bdff-5c7762b69d01 /etc/luks-keyfile/test luks,timeout=30
これで、起動時に自動でアンロックされるため、通常のHDDと同様に /etc/fstab にマウントポイントを記述しておくと、アンロックとマウントまで自動で行われる。
$ sudo vi /etc/fstab /dev/mapper/crypt-sdb1 /srv ext4 defaults 0 0
$ sudo reboot ...
$ df /dev/mapper/crypt-sdb1 ファイルシス 1K-ブロック 使用 使用可 使用% マウント位置 /dev/mapper/crypt-sdb1 8136484 24 7701568 1% /srv
ソフトウェアRAIDの透過的暗号
ソフトウェアRAIDと透過的暗号を組み合わせる場合、以下の2パターンがある。
- 暗号化ボリュームを使って、RAIDボリュームを作成 暗号化ボリュームを従来の物理HDDと同様に扱えるため、RAIDボリュームの管理や縮退時の対応が楽。ただし、HDDごとに暗号化ボリュームの構成が必要。
- RAIDボリュームを使って、暗号化ボリュームを作成 全てのHDDをひとつの暗号化ボリュームでまとめることができるが、RAIDボリュームの管理や縮退時の対応が難しい。
特に理由がなければ、前者が扱いやすい。この場合、特別な手順は必要なく、暗号化ボリュームに対して普通にRAIDの設定を行えば良い。
$ sudo lsblk -p /dev/sdc /dev/sdd NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS /dev/sdc 8:32 0 8G 0 disk └─/dev/sdc1 8:33 0 8G 0 part └─/dev/mapper/crypt-raid0 254:0 0 8G 0 crypt /dev/sdd 8:48 0 8G 0 disk └─/dev/sdd1 8:49 0 8G 0 part └─/dev/mapper/crypt-raid1 254:1 0 8G 0 crypt
$ sudo apt install mdadm
$ sudo mdadm --create --level=1 --metadata=1.2 --raid-devices=2 /dev/md0 /dev/mapper/crypt-raid0 /dev/mapper/crypt-raid1 mdadm: array /dev/md0 started.
$ sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf ARRAY /dev/md0 metadata=1.2 name=dmcrypt:0 UUID=07997157:3fd8cdc2:9fcf07a3:ce952c0f
$ sudo mdadm --assemble --scan
$ sudo lsblk -p /dev/sdc /dev/sdd NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS /dev/sdc 8:32 0 8G 0 disk └─/dev/sdc1 8:33 0 8G 0 part └─/dev/mapper/crypt-raid0 254:0 0 8G 0 crypt └─/dev/md0 9:0 0 8G 0 raid1 /dev/sdd 8:48 0 8G 0 disk └─/dev/sdd1 8:49 0 8G 0 part └─/dev/mapper/crypt-raid1 254:1 0 8G 0 crypt └─/dev/md0 9:0 0 8G 0 raid1
$ sudo mkfs -t ext4 /dev/md0
...
$ sudo blkid /dev/md0 /dev/md0: UUID="b9a593ff-3ea4-46aa-98fa-b93428a00fd1" BLOCK_SIZE="4096" TYPE="ext4"
$ sudo vi /etc/fstab UUID=b9a593ff-3ea4-46aa-98fa-b93428a00fd1 /opt ext4 defaults 0 0
$ sudo mount -a
$ sudo lsblk -p /dev/sdc /dev/sdd NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS /dev/sdc 8:32 0 8G 0 disk └─/dev/sdc1 8:33 0 8G 0 part └─/dev/mapper/crypt-raid0 254:0 0 8G 0 crypt └─/dev/md0 9:0 0 8G 0 raid1 /opt /dev/sdd 8:48 0 8G 0 disk └─/dev/sdd1 8:49 0 8G 0 part └─/dev/mapper/crypt-raid1 254:1 0 8G 0 crypt └─/dev/md0 9:0 0 8G 0 raid1 /opt
まとめ
- 保証期間内に壊れたHDDを修理に出せるようにするため、dm-crypt と LUKS を導入した
- セキュリティ対策としては機能しないが、HDDのみを提出する必要のあるケースにおいては、最低限の対策となると思う
Windowsでpovo2.0が「圏外」になる問題をATコマンドで解決する
GPD Win MAX2 の LTE モデルで povo 2.0 に繋ぎたい
先日、GPD Win MAX2 を購入した。当時、たまたま LTE 搭載モデルが最安だったので、povo 2.0 を契約して挿しておけば、旅行や出張が捗るのではと期待した。
しかし、povo 2.0 を契約し、SIM カードの挿入と APN 設定を行っても、ステータスは「圏外」となり LTE に接続できなかった。ググると以下のような設定方法を見つけられるが、自分にはいずれの方法も効果が無かった。
また、GPD のWebページからドライバを入手し、Windows 標準ドライバから LTEモデムのメーカ(Quectel)のドライバに更新したりもしたが、これも効果が無かった。
Windows11 の UI の問題?
上記で挙げたWebページをはじめ、世の中のバラバラな情報をかき集めると、以下の状況が見えてくる。
- MVNOやサブブランドのSIMでは「規定のAPN」が悪さをすることがある
- 5G対応のSIMでは「APNの種類」で「インターネットおよびアタッチ」を選ぶ必要がある
- 5G非対応のモデムでは「APNの種類」で「インターネット」しか表示されない
- 「インターネットとアタッチ」が表示される環境でも、まれに消えることがある
なんとなく、WWAN周りにおける Windows のユーザインタフェースの造りが甘いのでは?という問題が透けて見える。
AT コマンドで直接制御する
組み込み系ではよくやる方法だけども、LTEモデムやダイヤルアップモデムは、ATコマンドと呼ばれるコマンド群で制御ができる。インタフェース系の問題であれば、直接LTEモデムへコマンドを送ってしまえば設定できるのでは?と考えた。
検証環境
- Windows11 Home 22H2
- GPD WIN MAX2 (2022モデル)
- Quectel EC25-J
- RLogin 2.28.1
手順
LTEモデムに接続する
LTEモデムの多くは、UARTでATコマンドを受け付けているため、ここにシリアルコンソールで接続する。今回は Quectel USB AT Port に対して、ターミナルエミュレータの RLogin を用いて接続した。

接続できたら、AT コマンドで疎通を開始し、ATI コマンドでモデムの情報を取得する。
AT OK ATI Quectel EC25 Revision: EC25JFAR06A06M4G
モデムの情報が分かれば、メーカーサイトからデータシートを取得し、対応しているATコマンドを確認する。Quectel の EC25 ならば以下になる。
APNの設定を行う
まずは、現在の APN の状態を確認する。
AT OK AT+CGDCONT? +CGDCONT: 1,"IPV4V6","uno.au-net.ne.jp","0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0",0,0,0,0 +CGDCONT: 2,"IPV4V6","","0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0",0,0,0,0 +CGDCONT: 3,"IPV4V6","ims","0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0",0,0,0,0 +CGDCONT: 4,"IPV4V6","SOS","0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0",0,0,0,1 OK
自分は Windows11 の GUI から povo2.0 のWebページに記載されている設定 を行っているにも関わらず、 実際に LTE モデムに読み込まれている設定は KDDI の規定 のものになっている。そこで、LTEモデム上の不揮発メモリに対して、設定を上書きしてやる。
AT+CGDCONT=1,"IPV4V6","povo.jp" OK AT+CGDCONT? +CGDCONT: 1,"IPV4V6","povo.jp","0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0",0,0,0,0 +CGDCONT: 2,"IPV4V6","","0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0",0,0,0,0 +CGDCONT: 3,"IPV4V6","ims","0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0",0,0,0,0 +CGDCONT: 4,"IPV4V6","SOS","0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0",0,0,0,1 OK
その後、LTEモデムを再起動させて、15秒くらい待機する。
AT+QPOWD=1 OK POWERD DOWN
LTEモデムの再起動が完了すると、「圏外」だったステータスが接続済みとなる。

まとめ
Windows11で自作アプリをブラウザとして登録する
- Windows10以降では、「設定」から自作アプリや野良アプリをブラウザとして指定できない
- 任意の実行ファイルを規定のブラウザとして指定する手順を調査した
自作アプリをブラウザとして登録したい
自分は、Vivaldi を愛用しているが、業務システムの中にはブラウザを指定するものがある*1。
自分から能動的に使う場合は、ブラウザを呼び出すショートカットを使えば良いが、メールやチャット等で「このURLを開いてください」と言われると、URL のコピーペーストをしなければならない。これは大変ストレスフルである。
そこで、自作アプリを挿入し、URLを解釈してブラウザを切り替えようと思ったのだけど、作った実行ファイルを規定のブラウザとして登録できなかったので、その手順を調べてみた。
Windows10 以降でプロトコルの規定のアプリとして、自作アプリを紐付けるのどうやるん?
— kWatanabe (@WWatchin) 2023年2月3日
ここの一覧に任意の EXE を表示させたいのだが。誰か助けて。 pic.twitter.com/7utIpRGD4I
検証環境
- Windows 11 64bit 22H2
- 検証用の自作ツール(
C:\Apps\kwatanabe.exeに保存)
手順
レジストリエディタを多用するため、復元ポイントの作成や、サンドボックス環境での練習を強く推奨する。
アプリの ProgID を登録
まず、レジストリエディタを用いて、ProgID を登録する。以下の構造でキーとデータを作成する。
HKEY_LOCAL_MACHINESoftwareClasses- 任意の ProgID(今回は
kwatanabe.1とした)shellopencommand(規定)= コマンドライン文字列(今回は"C:\Apps\kwatanabe.exe" "%1"とした)
- 任意の ProgID(今回は
「規定のアプリ」候補としての情報を登録
引き続き、レジストリエディタを用いて、「規定のアプリ」候補としての情報を登録する。以下の構造でキーとデータを作成する。
HKEY_LOCAL_MACHINESoftware- アプリ名(今回は
kwatanabeとした)CapabilitiesApplicationDescription= アプリの説明文(今回はkwatanabe's appとした)FileAssociations(任意)- 「規定のアプリ」の候補としたい拡張子 = ProgID
(今回は省略。具体例としては.txt=kwatanabe.1)
- 「規定のアプリ」の候補としたい拡張子 = ProgID
UrlAssociations(任意)- 「規定のアプリ」の候補としたいスキーム = PorgID
(今回はhttp=kwatanabe.1とした)
- 「規定のアプリ」の候補としたいスキーム = PorgID
- アプリ名(今回は
拡張子やスキームは、HKEY_CLASSES_ROOT 配下に登録されているキーから指定する。不足している場合には、HKEY_LOCAL_MACHINE\Software\Classies 配下に追加する*2。
「規定のアプリ」候補として登録
引き続き、レジストリエディタを用いて、アプリを「規定のアプリ」候補として登録する。以下の構造でキーとデータを作成する。
HKEY_LOCAL_MACHINESoftwareRegisteredApplications- アプリ名 =
HKEY_LOCAL_MACHINEを起点としてCapabilitiesに至るまでのパス(今回はkwatanabe=Software\kwatanabe\Capabilitiesとした)
- アプリ名 =
「設定」アプリで「規定のアプリ」に設定
キャッシュを綺麗にするため、一度 Windows 再起動する。
その後、プロトコル単位での規定のアプリの設定画面*3を辿ると、登録したアプリが一覧に表示される。

まとめ
TweetDeckをブラウザの機能でアプリ化する
Twitter がサードパーティアプリを締め出し
2022/1/13 頃に Twitter のサードパーティアプリが一斉にアクセスできない事象が発生。その後、1/19 に Twitter が Developers Agreement を更新し、サードパーティアプリの開発を禁止するような文言が追加される事件が発生した。
該当箇所は以下。
II. Restrictions on Use of Licensed Materials A. Reverse Engineering and other Restrictions. ...(省略)... You will not or attempt to (and will not allow others to) ...(省略)... c) use or access the Licensed Materials to create or attempt to create a substitute or similar service or product to the Twitter Applications;
今後、どういう状況になるかは不明だけども、あまり未来は明るくなさそうに感じる。
Twitter 公式アプリ
1/20 現在では、動作しているサードパーティアプリもあるものの、以下の Twitter 社公式のクライアントを使わざるを得なくなると予想される。
個人的には、
- 変な広告がでない
- 時系列にツイートが流れる
- リスト表示がきちんとしている
点から、TweetDeck が一番マトモだと感じており、実はこの事案が発生する以前から、PC では TweetDeck を使っていた。
しかし、Twitter をするために、ブラウザを開き、ブックマークを選ぶ、という作業は億劫だし、ネイティブアプリのように扱いたい。
PWA ( Progressive Web Application )
PWA ( Progressive Web Application ) は、ブラウザやそのエンジンを使って、Web アプリをあたかもネイティブアプリのように見せかける仕組み。クロスプラットフォームで扱うアプリで採用されている。 また、Chrome ベースのブラウザであれば、任意のWebサイトをブラウザ自身の機能で簡易的に PWA 風にできる。
ブラウザの機能で PWA 化すれば、ブラウザ特有のインタフェースも隠蔽され、ネイティブアプリのように扱える。そこで、TweetDeck をブラウザの機能で PWA 化してみることにした。
検証
Android + Chrome
- TweetDeckを開き
- 設定ボタンから「ホーム画面に追加」を選択
- ホーム画面に出現した「TweetDeck」アイコンを押下


結果、以下のようにネイティブアプリ風の TweetDeck ができあがる。

Android + Opera
Chromeベースのブラウザであれば、だいたい同じ作法で PWA 化できる。
- 設定ボタンから「アイテムの追加」→「ホーム画面」を選択
Android + Vivaldi
- 設定ボタンから「ホーム画面に追加」を選択

Windows + Chrome
PC でも PWA 化は可能。
- 設定ボタン
- 「その他のツール」を押下
- 「ショートカットを作成」を押下
- 「ウィンドウとして開く」にチェック


このように PC でも可能。
タスクバーでも、本物のアプリのように見える。

その他の環境
今後、Mac とか iPhone とかの他の環境でも、試してみる予定。
おわりに
- TweetDeck をネイティブアプリのように使う方法を整理した
- TweetDeck も元々はサードパーティアプリだったので、なんとも皮肉な結果になったと感じた。
urlwatchでwebサイトを監視してSlackで通知する
- これまで Zabbix で行っていた Web サイトの更新確認を urlwatch に変更した
- cron による自動実行と Slack 連携で、自動でスマホに通知する仕組みを作る

Webサイトの更新確認を楽に行いたい
以前、以下のエントリでも投稿した通り、株価の監視やコロナワクチン情報サイトの監視に Zabbix を使ってきた。
Zabbix はサーバやサービスを監視するツールで、Web サイトの更新をただ監視するにはオーバスペックであり、そのため多くの設定が必要で保守が面倒だった*1。もっと手軽に使えるツールが欲しかった。
株価の判定のように、その時点の情報のみで完結するようなものは、n8n workflow などのローコード系のワークフローシステムが使いやすい。一方、Webサイトの更新検知においては、前回の情報との照合が必要なため、外部データベースやストレージを用意することになり、これは別の意味で面倒くさい。
そこで、Webページの更新監視に特化した urlwatch を試してみた。Webサーバの更新を検知したら、Slack 経由でスマホに通知して欲しいので、Slack 連携も設定した。
検証環境
手順
Slack の webhook URL を取得
Slack のアカウント、ワークスペース、チャネルは事前に構築済みとする。
- Slackにログイン
- Slack API から新規 Slack アプリを作成
- Create New App を押下
- From scratch を押下
- AppName に任意の名称を入力
- Pick a workspace to develop your app in: に投稿したい Slack ワークスペースを選択
- Create App を押下
- Features の Incoming Webhooks を押下
- Activate Incoming Webhooks を On
- Add New Webhook to Workspace を押下
- 権限リクエストで投稿先のチャネルを指定したうえで許可
- Webhook URL をコピー
正しく作成できているか確認するのであれば、curl で以下のようにすればテストができる。
$ curl -X POST -H 'Content-type: application/json' --data '{"text":"Hello, World!"}' WebHookのURL`
urlwatch の導入
Debian であれば apt で導入できる。最新版が使いたいなら pip で導入する。
$ sudo apt update $ sudo apt install urlwatch
urlwatch はサービスではなく単体起動するコマンドラインツールなので、設定ファイルはユーザのホームディレクトリに作成する構成が標準となっている。
今回は、監視からSlack通知まで自動化をしたいので、システムに設定ファイル用のディレクトリを用意しておく。
$ sudo mkdir /etc/urlwatch
設定ファイルの初期ファイルを生成させる。デフォルトの設定ファイルから保存場所を変更するため、パスを指定する。
$ sudo urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml
A default config has been written to /etc/urlwatch/config.yaml.
Use "urlwatch --edit-config" to customize it.
You need to create /etc/urlwatch/urls.yaml in order to use urlwatch.
Use "urlwatch --edit" to open the file with your editor.
Slack 通知を有効化するため、設定ファイルを編集する。
$ sudo urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml --edit-config
... report: ... slack: enabled: true max_message_length: 40000 webhook_url: 'WebHookのURL' ...
監視用のURLを登録する。1つの yaml で複数項目を列挙する仕様となっているため、監視対象ごとに --- で区切って列挙する。ここでは、何かしら更新されたら通知する設定を行う。
$ sudo urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml --edit
kind: url name: "テストページ" url: "テストページのURL" --- kind: url name: "テストページ2" url: "テストページ2のURL"
ほかにも、正規表現でマッチする箇所のみを監視したりやシェルスクリプトの実行結果での通知など、高度な設定もできる。詳細は公式のドキュメントを参照。
設定を認識しているか確認する。
$ sudo urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml --list 1: テストページ ( テストページのURL ) 2: テストページ ( テストページ2のURL )
動作確認
urlwatch を実行する。これまで実行したことない項目があれば、それが検知される。
$ sudo urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml =========================================================================== 01. NEW: テストページ 02. NEW: テストページ2 =========================================================================== --------------------------------------------------------------------------- NEW: テストページ ( テストページのURL ) --------------------------------------------------------------------------- --------------------------------------------------------------------------- NEW: テストページ2 ( テストページ2のURL ) ---------------------------------------------------------------------------
もし、前回実行時から更新されていれば、以下のように検知される。
$ sudo urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml =========================================================================== 01. CHANGED: テストページ =========================================================================== --------------------------------------------------------------------------- CHANGED: テストページ ( テストページのURL ) ---------------------------------------------------------------------------
また、コンソールに出力されている内容と同じものが、Slack にも投稿される。
Slack 向けに体裁を整える
標準の出力はコンソールで実行する分には問題ないが、Slackに投稿されると通知が見づらいので、出力を小型化する。
$ sudo urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml --edit-config
... report: ... text: ... minimal: true ...
これで、出力が以下のように小型化される。
$ sudo urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml CHANGED: テストページ ( テストページのURL )
cron に登録
urlwatch はコマンドラインツールなので、cron から定期起動して更新を自動的に通知するように設定する。
$ sudo crontab -e 11,26,41,56 * * * * urlwatch --urls /etc/urlwatch/urls.yaml --config /etc/urlwatch/config.yaml > /var/log/urlwatch.log
まとめ
- 設定ファイルの更新のみで手軽に監視対象の保守できる、Webサイト監視の仕組みを構築できた。
- 株価の監視のような、Web API をたたいて値を監視するような用途だと、n8n workflow や IFFTT のようなローコード系のワークフローシステムを使った方が、やりやすいと思う。
*1:サーバ、サービス監視には多機能、かつ、使いやすくて重宝している。コロナワクチン1回目がなかなか受けられなかった頃に、元々使っていた Zabbix に相乗りさせたくて、無理矢理作り込んだ経緯がある。
KVMホストをLXCコンテナの中に構築する
背景
我が家には、常時稼働の本番用のサーバと、必要な時に電源を入れる開発用のサーバがある。前者は Debian11 + LXC で、後者は Proxmox VE (KVM+LXC) で運用している。
ちょっとした検証等は常時稼働のサーバでやりたい*1が、本番環境に怪しいコンテナを作るのも嫌なので、KVMでサンドボックス化したい。一方、本番環境では KVM を使っておらず、不必要なものでホストOSを汚したくない。
そこで、KVM を使える コンテナを構築して、その中に Proxmox VE を導入しようと考えた。
検証環境
なお、本番サーバへの適用前に、開発用サーバ上の VM で検証したので、実際には以下のような構成となった。

KVM ホスト化
方針
大まかな方針としては、KVMの動作に必要なデバイスファイルを、LXC コンテナの中から扱えるようにする。以前、LXC コンテナ内で GPGPU するために採った策と基本的には同じ。
コンテナの作成と健全性確認
Proxmox VE 化は後からするとして、まずは普通の Debian 11 コンテナを作り。
$ sudo lxc-create -n kvm-in-container -t download -- -d debian -r bullseye -a amd64
起動する。
$ sudo lxc-start -n kvm-in-container
KVMやLXCをホストできるか検証してくれる virt-host-validate コマンドを導入する。
$ sudo lxc-attach -n kvm-in-container -- apt install libvirt-clients
何も対策していない素の状態だと以下の通り。
$ sudo lxc-attach -n kvm-in-container -- virt-host-validate setlocale: No such file or directory QEMU: Checking for hardware virtualization : PASS QEMU: Checking if device /dev/kvm exists : FAIL (Check that the 'kvm-intel' or 'kvm-amd' modules are loaded & the BIOS has enabled virtualization) QEMU: Checking if device /dev/vhost-net exists : WARN (Load the 'vhost_net' module to improve performance of virtio networking) QEMU: Checking if device /dev/net/tun exists : FAIL (Load the 'tun' module to enable networking for QEMU guests) QEMU: Checking for cgroup 'cpu' controller support : PASS QEMU: Checking for cgroup 'cpuacct' controller support : PASS QEMU: Checking for cgroup 'cpuset' controller support : PASS QEMU: Checking for cgroup 'memory' controller support : PASS QEMU: Checking for cgroup 'devices' controller support : PASS QEMU: Checking for cgroup 'blkio' controller support : PASS QEMU: Checking for device assignment IOMMU support : WARN (No ACPI IVRS table found, IOMMU either disabled in BIOS or not supported by this hardware platform) QEMU: Checking for secure guest support : WARN (Unknown if this platform has Secure Guest support) LXC: Checking for Linux >= 2.6.26 : PASS LXC: Checking for namespace ipc : PASS LXC: Checking for namespace mnt : PASS LXC: Checking for namespace pid : PASS LXC: Checking for namespace uts : PASS LXC: Checking for namespace net : PASS LXC: Checking for namespace user : PASS LXC: Checking for cgroup 'cpu' controller support : PASS LXC: Checking for cgroup 'cpuacct' controller support : PASS LXC: Checking for cgroup 'cpuset' controller support : PASS LXC: Checking for cgroup 'memory' controller support : PASS LXC: Checking for cgroup 'devices' controller support : PASS LXC: Checking for cgroup 'freezer' controller support : FAIL (Enable 'freezer' in kernel Kconfig file or mount/enable cgroup controller in your system) LXC: Checking for cgroup 'blkio' controller support : PASS LXC: Checking if device /sys/fs/fuse/connections exists : PASS
対策すべきは以下の項目。
/dev/kvmが無い/dev/vhost-netが無い/dev/net/tunが無い
あと、/dev/fuse が無くて Proxmox VE 化する際に失敗するため、合わせて対応する。単なる KVM ホストとしての動作には必須では無いので、その場合はスルーでよい。
それぞれ、ホストでデバイス番号を調べておく。
$ ls -l /dev/kvm /dev/vhost-net /dev/net/tun /dev/fuse crw-rw---- 1 root kvm 10, 232 10月 30 10:05 /dev/kvm crw-rw-rw- 1 root root 10, 200 10月 30 10:05 /dev/net/tun crw------- 1 root root 10, 238 10月 30 10:05 /dev/vhost-net crw------- 1 root root 10, 229 10月 30 10:05 /dev/fuse
コンテナ定義ファイルの修正
一旦コンテナを終了させる。
$ sudo lxc-stop -n kvm-in-container
次に、コンテナの定義ファイル /var/lib/lxc/<コンテナ名>/config を編集する。
$ sudo vim /var/lib/lxc/kvm-in-container/config
LXCをネストさせるための設定。
lxc.include = /usr/share/lxc/config/common.conf lxc.include = /usr/share/lxc/config/nesting.conf lxc.apparmor.profile = unconfined lxc.apparmor.allow_nesting = 1
必要なデバイスファイルへのアクセス権を与える設定。
lxc.cgroup.devices.allow = c 10:232 rwm lxc.cgroup.devices.allow = c 10:200 rwm lxc.cgroup.devices.allow = c 10:238 rwm lxc.cgroup.devices.allow = c 10:229 rwm lxc.cgroup2.devices.allow = c 10:232 rwm lxc.cgroup2.devices.allow = c 10:200 rwm lxc.cgroup2.devices.allow = c 10:238 rwm lxc.cgroup2.devices.allow = c 10:229 rwm
ホストのデバイスファイルを bind mount する設定。なお、bind mount せずに、コンテナの中で mknod コマンドでデバイスファイルを作成するのでもよい。
lxc.mount.entry = /dev/kvm dev/kvm none bind,optional,create=file lxc.mount.entry = /dev/net/tun dev/net/tun none bind,optional,create=file lxc.mount.entry = /dev/vhost-net dev/vhost-net none bind,optional,create=file lxc.mount.entry = /dev/fuse dev/fuse none bind,optional,create=file
コンテナの再起動と健全性再確認
コンテナを再起動する。
$ sudo lxc-start -n kvm-in-container
改めて virt-host-validate コマンドで確認する。
$ sudo lxc-attach -n kvm-in-container -- virt-host-validate setlocale: No such file or directory QEMU: Checking for hardware virtualization : PASS QEMU: Checking if device /dev/kvm exists : PASS QEMU: Checking if device /dev/kvm is accessible : PASS QEMU: Checking if device /dev/vhost-net exists : PASS QEMU: Checking if device /dev/net/tun exists : PASS QEMU: Checking for cgroup 'cpu' controller support : PASS QEMU: Checking for cgroup 'cpuacct' controller support : PASS QEMU: Checking for cgroup 'cpuset' controller support : PASS QEMU: Checking for cgroup 'memory' controller support : PASS QEMU: Checking for cgroup 'devices' controller support : PASS QEMU: Checking for cgroup 'blkio' controller support : PASS QEMU: Checking for device assignment IOMMU support : WARN (No ACPI IVRS table found, IOMMU either disabled in BIOS or not supported by this hardware platform) QEMU: Checking for secure guest support : WARN (Unknown if this platform has Secure Guest support) LXC: Checking for Linux >= 2.6.26 : PASS LXC: Checking for namespace ipc : PASS LXC: Checking for namespace mnt : PASS LXC: Checking for namespace pid : PASS LXC: Checking for namespace uts : PASS LXC: Checking for namespace net : PASS LXC: Checking for namespace user : PASS LXC: Checking for cgroup 'cpu' controller support : PASS LXC: Checking for cgroup 'cpuacct' controller support : PASS LXC: Checking for cgroup 'cpuset' controller support : PASS LXC: Checking for cgroup 'memory' controller support : PASS LXC: Checking for cgroup 'devices' controller support : PASS LXC: Checking for cgroup 'freezer' controller support : FAIL (Enable 'freezer' in kernel Kconfig file or mount/enable cgroup controller in your system) LXC: Checking for cgroup 'blkio' controller support : PASS LXC: Checking if device /sys/fs/fuse/connections exists : PASS
問題なし。ここまできたら、後は qemu-kvm や virt-manager などを導入し、通常の KVM ホストと同じように扱える。
Proxmox VE 化(おまけ)
Debian 11 を Proxmox VE 化する際は以下のWebページが参考になる。
ただ、今回はコンテナなので、専用カーネルでの差し替えはできない。詳細は割愛するが、大まかな流れは以下となる。
$ sudo lxc-start -n kvm-in-container $ sudo lxc-attach -n kvm-in-container -- systemctl disable systemd-networkd systemd-resolved $ sudo lxc-stop -r -n kvm-in-container $ sudo lxc-attach -n kvm-in-container -- rm /etc/resolv.conf $ sudo lxc-attach -n kvm-in-container -- vim /etc/resolv.conf nameserver <DNSサーバのIPアドレス> search <検索ドメイン名> $ sudo lxc-attach -n kvm-in-container -- vim /etc/hosts <コンテナのIPアドレス> kvm-in-container $ sudo lxc-attach -n kvm-in-container -- dpkg-reconfigure locales <任意のロケールを選択> $ sudo lxc-attach -n kvm-in-container -- apt install wget $ sudo lxc-attach -n kvm-in-container -- vim /etc/apt/sources.list.d/pve-install-repo.list deb [arch=amd64] http://download.proxmox.com/debian/pve bullseye pve-no-subscription $ sudo lxc-attach -n kvm-in-container -- wget https://enterprise.proxmox.com/debian/proxmox-release-bullseye.gpg -O /etc/apt/trusted.gpg.d/proxmox-release-bullseye.gpg $ sudo lxc-attach -n kvm-in-container -- apt update $ sudo lxc-attach -n kvm-in-container -- apt full-upgrade $ sudo lxc-attach -n kvm-in-container -- apt install proxmox-ve
結果
こんな感じに仕上がった。
KVM on LXC on KVM 環境に、Proxmox VE を入れて、VM を作ることに成功した。実はホストも Proxmox VE なので、これで、Proxmox VE with KVM on LXC on Proxmox VE with KVM になった。
— kWatanabe (@WWatchin) 2022年11月21日
パススルーしすぎて、中央の LXC の中で virt-what を叩いたら、LXCとKVM の両方だと判定された。もはやカオス。 https://t.co/cgcn9BHQ1m pic.twitter.com/rI0NuyVwVT
まとめ
*1:目の前のマシンに Docker 入れればええやん、とか言わないで。禁止。
画面のないLXCコンテナでGUI環境を構築する
- 画面のない LXC コンテナで xfce4 のデスクトップ環境を構築する
- WSL2 や Docker コンテナでも同じ要領でできるはず
LXCコンテナでGUIが使いたい
我が家の自宅サーバは LXC コンテナで運用している。ホスト計算機はヘッドレスなので、GUI環境はインストールしていない。基本的には SSH で十分だし、そもそもヘッドレスということは作業マシンが別にあるわけで、コンテナに GUI 環境は必要ない。
ただ、出先から自宅にリモートログインした場合に、ちょっとした GUI アプリを使いたい場合など、まれにコンテナに GUI があったらな、と思うこともある。
そこで、必要なときにだけ起動する GUI を含んだ LXCコンテナを作ることにした。
検証環境
手順
デスクトップ環境の導入
好みのデスクトップ環境を選ぶ。個人的には、サーバは非力というわけでもない*1し、それなりに使いやすいものがいいので、xfce4 を選ぶ。
$ sudo apt install xfce4 xfce4-goodies $ echo "xfce4-session" > ~/.xsession
日本語入力環境も整えるが、普段使いするわけでもない、リモートから必要なときにだけ使うものなので、チューニングに時間はかけずにサクッと導入できるものを選ぶ。
$ sudo apt install task-japanese task-japanese-desktop ibus-kkc locales-all $ sudo localectl set-locale LANG=ja_JP.UTF-8 LANGUAGE="ja_JP:ja"
これはおまけ。ファイラーから、ファイルサーバの samba につなげるようにしたいので、GVFS も入れておく。
$ sudo apt install gvfs-backends
xrdp の導入
LXC コンテナは画面を持たないので、もちろんフレームバッファもない。そのため、リモートフレームバッファを作る。自分は外出時には GPD Pocket 2 を使うので、VNC より Windows リモートデスクトップ で繋ぎたい。そのため、xrdp を導入し、xvnc セッションに RDP 接続できるようにする。
xvnc 含めて、必要なパッケージは依存関係で入るので、導入はシンプル。
$ sudo apt install xrdp
コンテナを再起動。
$ sudo reboot
リモートデスクトップ接続
適当な Windows マシンから RDP 接続する。後は言語切り替え*2や、キーボード配列*3などを好みの通り修正すれば完了。

まとめ
- ホストもゲストも画面を持たない、LXCコンテナに xfce4 の GUI 環境を構築した
- LXC コンテナ特有の操作はないため、WSL2 や Docker、systemd-nspawn など、他のヘッドレス環境でも同じ手順で構築できる・・・かもしれない。
噂のお絵かきAI「Stable Diffusion」をローカルで動かす
- 噂になっているお絵かきAI「Stable Diffusion」のデモサイトは順番待ちがあり自由に試せない
- ローカルマシンに導入して、好きなだけ試せる環境を構築する
お絵かきAI「Stable Diffusion」
キーワードを与えると、それに準じた画像を自動生成してくれる凄いヤツ。
無料で試せるデモサイトもある。
デモサイトで少し遊んでいたのだけども、他の利用者と順番待ちがあるらしく、細かくテキストをいじって試すには、中々まだるっこしい。
ということで、ローカルに環境を構築した。
検証環境
- Debian 11.4 (bullseye) amd64
- NVIDIA GeForce RTX 3080 (初代)
- nvidia-cuda-toolkit 11.2.2-3+deb11u3
- nvidia-driver 470.129.06-6~deb11u1
- python 3.9.2
ちなみに、公式ページの記述によると少なくとも VRAM を 10GB 搭載した GPU が必要らしい。自分の RTX 3080 は初代なのでギリギリセーフ。(本当はギリギリアウトだが、後述する回避策で乗り切った)
手順
Anaconda 3 の導入
Anaconda の公式サイトから、インストーラをダウンロードして導入する。
$ wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh $ chmod +x Anaconda3-2022.05-Linux-x86_64.sh $ ./Anaconda3-2022.05-Linux-x86_64.sh
自分は普段使いのシェル( zsh )とは別に fish を導入して、Anaconda 専用のシェルにした。
$ sudo apt install fish $ ~/anaconda3/bin/conda init fish
Stable Diffusion の導入
$ fish $ git clone https://github.com/CompVis/stable-diffusion.git $ cd stable-diffusion $ conda env create -f environment.yaml $ conda activate ldm $ conda install pytorch torchvision -c pytorch $ pip install transformers==4.19.2 diffusers invisible-watermark $ pip install -e .
モデルを入手する
モデルは、AI 系開発コミュニティの Hugging Face のリポジトリで公開されているため、まずはアカウントを作成する。
アカウントが作成できたら、モデルの公開リポジトリにアクセスする。その後、ライセンス条項を確認し、同意できるならば「Access Repository」を押下する。
リポジトリにアクセスしたら、sd-v1-4.ckpt のリンクを押下して、モデルをダウンロードする。ダウンロードしたファイルは stable-diffusion の展開先ディレクトリ配下に models/ldm/stable-diffusion-v1/model.ckpt という名前で格納する。
$ cd stable-diffusion $ mkdir -p models/ldm/stable-diffusion-v1
試す
とりあえず、「女の子と猫」というキーワードで画像生成してみる。
$ python ./scripts/txt2img.py --prompt 'girl and cat' --plms
上記のコマンドだと、自分の場合は、以下のような VRAM 不足のエラーが発生した。初代 GeForce RTX 3080 は要求スペックギリギリなので、仕方ない。
RuntimeError: CUDA out of memory. Tried to allocate 3.00 GiB (GPU 0; 9.78 GiB total capacity; 5.62 GiB already allocated; 2.56 GiB free; 5.74 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
以下のように、積極的にメモリ回収を行うオプションをつけ、一度に生成するサンプルを制限することで実行できた。
$ PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:128 \
python scripts/txt2img.py --prompt 'girl and cat' --plms --n_samples 1
出力された画像は以下の通り。確かに、女の子と猫だ!!

なお、生成にかかった時間は、10秒くらい。
余談
自分が Stable Diffusion の存在を知るのが遅すぎて、すでに世の中の人が GPU なしでも使えるものとか、GUI で簡単に扱えるようにしたものとかを色々リリースしているみたい。 CPU だと数秒とはいかないだろうけど、ちょっと試す分にはいいかも。
更に余談
ローカルで遊べるようになったので、みんながやってるみたいにアニメ調の女の子を生成しようと頑張ったけど。このあたりで挫折。
お絵かきAIが、ローカルで使えるようになったので、今度はイラスト調の可愛い女の子を生成しようと遊んでいたけど、この辺で挫折。
— kWatanabe (@WWatchin) 2022年9月3日
なんだろ、そんな指定してないのに、関節とかが何故かドールみたいになっとる。ローゼンメイデン?? https://t.co/AGkWoOQRre pic.twitter.com/FiI5SVKzlu
まとめ
オムロン製UPS「BY50S」を Debian 11 で使う
- オムロン製UPS「BY50S」は比較的安価で使いやすい製品だが、同梱の Linux 向けの自動シャットダウンツールは RHEL 系しかサポートしていない。
- BY50S向け自動シャットダウンツールの「SimpleShutdownSoftware」を Debian 11 (bullseye) で使えるようにした。
BY50S は Debian系Linuxをサポートしていない
オムロン社製UPSの「BY50S」は、実売価格18000円ほどで品質も必要十分なので、自宅サーバや録画機器などで使いやすい。
BY50S 向けの自動シャットダウンツールとしては、エージェントとマネージャで複数のサーバを統合管理できる「PowerAct」と、UPSと直接会話するデーモンで単体のサーバのシャットダウンだけを行う「SimpleShutdownSoftware」が提供されている。
しかし、いずれも対応OSが Windows、RHEL系Linux、macos で、Debian系Linux はサポート外となっている。
一方、 kWatanabe の自宅サーバは Debian で稼働している。そこで、「SimpleShutodownSoftware」を Debian で使うための手順を整理した。
Debian 11 で SimpleShutdownSoftware を使う
検証環境
手順
必要なパッケージを導入する。
# apt install wget unzip libusb-dev build-essential
オムロン社のWebページから「Simple Shutdown Software Ver 2.41(Linux版)」を入手し、 /usr/local/src に配置する。
# cd /usr/local/src # wget https://socialsolution.omron.com/jp/ja/products_service/ups/support/download/soft/sss/SimpleSoftwareVer241_Linux_X64.zip # unzip SimpleSoftwareVer241_Linux_X64.zip # mv SimpleSoftwareVer241_Linux_X64 SimpleShutdownSoftware
Release/master 配下に RHEL7 向けのバイナリが保存されている。これが動作する環境ならば、そのまま利用してもよい。リビルドする場合には、以下のように Source ディレクトリに移動してビルドする。
# cd ./SimpleShutdownSoftware/Source # make -j`nproc` # cd ../Release # ls master AgentManager* Shutdown.cfg* SimpleShutdownDaemon* UsbPort-Libusb.so.1.0.0* my_kvm.sh* ssdDaemon* S99SimpleShutdown* SimpleShutdown* UsbPort-HID.so.1.0.0* config.sh* omronctl* ssdService*
バイナリの配置と設定ファイルの生成のために、インストールスクリプトを実行する。
# ./install.sh Do you agree this license? [ y/n ] y
設定スクリプトを用いて、ファイルをしかるべき値に設定する。我が家の場合は /srv/scripts/emergency/emergency-shutdown.sh を叩くと、全てのサーバがクリーンにシャットダウンできる仕組みを整えているので、これをキックする設定を行う。
# /usr/lib/ssd/master/config.sh ... ******************************************************************************** [Reconfirm shutdown parameter of the marine (Master Agent)]. ******************************************************************************** 1. Port Selection Mode: Semiautomatic Mode(Only select all USB device) 2. Select USB communication mode : Libusb 3. AC fail Delay time (Sec): 5 4. External Command Line: /srv/scripts/emergency/emergency-shutdown.sh 5. External Command needs time (Sec): 60 6. OS Shutdown needs time (Sec): 60 7. Send Message to login users: Enable 8. System closing mode : Shutdown 9. Virtual Server shutdown mode : Shutdown by Linux System ******************************************************************************** Select Number:1
これで、一見インストールされデーモンが起動するようにみえるが、自動起動がうまく設定されておらず、システムを再起動すると起動に失敗する。そのため、Debian 11 の環境に合わせて処置する。
まず、インストールスクリプトで導入された壊れている rc ファイルを削除する。
# find /etc/rc?.d | grep SimpleShutdown | xargs rm -v '/etc/rc1.d/S99SimpleShutdown' を削除しました '/etc/rc2.d/S99SimpleShutdown' を削除しました '/etc/rc3.d/S99SimpleShutdown' を削除しました '/etc/rc5.d/S99SimpleShutdown' を削除しました
削除した rc ファイルに変わる systemd ユニットファイルを作成する。
# vim /etc/systemd/system/SimpleShutdown.service [Unit] Description=Simple Shutdown Software [Service] Type=forking ExecStart=/usr/lib/ssd/master/ssdService KillSignal=SIGUSR1 Restart=on-abort RestartSec=3 [Install] WantedBy=multi-user.target
作成したユニットファイルを読み込ませて、システムを再起動する。
# systemctl daemon-reload # systemctl enable SimpleShutdown.service # reboot
再起動後、デーモンが起動していることを確認する。
# systemctl status SimpleShutdown ● SimpleShutdown.service - Simple Shutdown Software Loaded: loaded (/etc/systemd/system/SimpleShutdown.service; enabled; vendor preset: enabled) Active: active (running) since Sat 2022-07-23 13:21:08 JST; 14min ago Process: 683 ExecStart=/usr/lib/ssd/master/ssdService (code=exited, status=0/SUCCESS) Main PID: 699 (ssdService) Tasks: 1 (limit: 154419) Memory: 2.1M CPU: 873ms CGroup: /system.slice/SimpleShutdown.service └─699 /usr/lib/ssd/master/ssdService 7月 23 13:21:08 marine systemd[1]: Starting Simple Shutdown Software... 7月 23 13:21:08 marine systemd[1]: Started Simple Shutdown Software. 7月 23 13:21:08 marine SimpleShutdown[699]: Shutdown Agent Start.
UPSを接続して、認識していることを確認できたら、UPSの電源を抜いて動作確認する。
# lsusb Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 003: ID 0590:0081 Omron Corp. BY50S Bus 001 Device 005: ID 046b:ff10 American Megatrends, Inc. Virtual Keyboard and Mouse Bus 001 Device 004: ID 046b:ffb0 American Megatrends, Inc. Virtual Ethernet Bus 001 Device 002: ID 046b:ff01 American Megatrends, Inc. Virtual Hub Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
まとめ
- BY50S 同梱の SimpleShutodownSoftware を Debian 11 で使えるようにする手順を整備した。
- systemd でデーモンを制御できるようにしたが、 udev などで頑張ることもできるかもしれない。
RockyLinuxとCentOS/RHELで ansible_os_family の挙動が異なる件
- CentOSやRHELで問題無い Ansible Playbook が RockyLinux が動かなかった
- 原因を調べると
ansible_os_familyの挙動が異なることが分かった - 【追記】この問題を修正するパッチが投稿されている模様
コトのはじまり
お手製の Ansible Playbook を Rocky Linux 8 に適用しようとしたときだった。
内容は大したことなくて、 /etc/yum.conf *1 にプロキシ設定を加えて、パッケージをアップデートするだけのものなのだけど、CentOS8 でも RHEL8 でも動くのに RockyLinux8 では動かない。
... TASK [basicpack : YUMプロキシ設定の追加] ********************************************************************************************* changed: [centos8.local] skipping: [rocky8.local] ...
この時、RHEL系なのか、Debian系なのかを振り分けるために when 句で判断してるんだけど、その結果が false になってしまっているようだった。
RockyLinuxは、CentOS と同じように RHEL のクローンのはずなのに、どうしてこういうことが起こるのか。
検証
検証環境
- RockyLinux 8.5
- Ansible 2.9.16
when を眺める
該当の task は以下のように実装してある。
- name: YUMプロキシ設定の追加 lineinfile: dest: /etc/yum.conf state: present regexp: '^proxy' line: 'proxy=http://{{ server_yum_proxy}}/' create: yes when: "ansible_os_family == 'RedHat' and server_yum_proxy is defined"
server_yum_proxy は、環境ごとに切り替わる vars でプロキシサーバのホスト名とポート番号を指定するようにしている。これが定義されていて、且つ、ansible_os_family ( 参考 ) で RedHat 系列であれば*2、プロキシを通すように設定している。
RHELの時はここは RedHat となっていた。CentOS でもずっと同じだったので、てっきり RockyLinux でも同じだと思っていた。
試してみる
動作検証用に以下のような Playbook を用意しているので、これで確認してみる。
- name: OS確認 debug: msg: "{{ ansible_distribution }}{{ ansible_distribution_version }} , {{ ansible_distribution }}{{ ansible_distribution_major_version }} , {{ ansible_distribution }} , {{ ansible_os_family }}"
結果は以下。
TASK [ping : OS確認] **********************************************************************************************************
ok: [rocky8.local] => {
"msg": "Rocky8.5 , Rocky8 , Rocky , Rocky"
}
なんと! ansible_os_family が RedHat ではなく Rocky になっている。ここは、互換じゃないのか!
対応
というわけで、問題の when 句を以下のように改修した。
when: "(ansible_os_family == 'RedHat' or ansible_os_family == 'Rocky') and server_yum_proxy is defined"
所感
追記
どうやら、これは不具合らしく、この問題に対応するパッチをマージする pull request が投稿されていた。
上記の通り、私の環境は 2.9.16 (Debianのbuster-backports で提供されているもの)でのものなので、最新版では正しく RedHat となるかもしれない。
fastapi-code-generatorで任意のフォーマットのコードを生成する
FastAPIとOpenAPI
先日、以下の記事で楽に自作 API を作れる FastAPI が動く環境を整備した。
さらに調べているうちに OpenAPI Spec から FastAPI 向けのコードジェネレータである「fastapi-code-generator」があることを知った。
OpenAPI ( 別名 Swagger ) は、API 仕様を策定するための規格で、この規格に準じた spec ファイルを作成するとドキュメントの自動生成や、フロントエンド、バックエンドのソースコードの自動生成ができる。

これはすこぶる便利だが、少し使ってみると困ったことが起こることに気づく。
OpenAPI Spec からのコード生成で困ったこと
fastapi-code-generator は OpenAPI Spec を与えると、ソースコードのスケルトンを生成してくれる。以下のように使う。
$ fastapi-codegen -i <APISpecファイル> -o <出力先ディレクトリ>
その結果、スケルトン本体の main.py と、クラス化したパラメータを集めた models.py が生成される。例えば、/token への POST メソッドを用いる API を定義した OpenAPI Spec を与えると以下のようになる。
from __future__ import annotations from typing import Optional, Union from fastapi import FastAPI, Header from .models import TokenPostRequest app = FastAPI( ...(省略)... ) @app.post('/token', response_model=TokenPostResponse) def post_token(body: TokenPostRequest = None) -> TokenPostResponse: """ トークンの取得 """ pass
ここの pass のところに実際のAPI処理を記述していくことになるのだけども、実装した後に新たなAPIを追加して fastapi-codegen すると、また pass に逆戻りしてしまう。また、グローバルなスコープに別のライブラリやDBアクセスのコードを足すと、それも消えてしまう。
仕様が変更された場合には致し方ないが、全く無関係な API が追加された場合にも、手作業でコピペする羽目になるのはいただけない。main.py にはインタフェースのみ記述して、実際の処理は別ファイルに外出ししたいし、グローバルなスコープのコードは維持したい。
コードテンプレートを使う
fastapi-code-generator では、-t オプションでコードテンプレートを指定できる。コードテンプレートは jinja2 形式で記述し、生成するコードのフォーマットを任意に定義できる。公式のドキュメントページに使える変数の一覧と、デフォルトテンプレートが記載されている。
この仕組みを使えば、グローバルなコードはテンプレートに直書きすればいいし、APIの処理ルーチンは pass を do_post_token() みたいなメソッドにし、実体を別ファイルに作成して import すればよい。
何も考えずに使うと失敗する
メソッド名は operation.function_name、引数は operation.snake_case_arguments で取れる。そこで、デフォルトテンプレートの pass に相当する箇所を素直に変更する。
return do_{{operation.function_name}}( {{operation.snake_case_arguments}} )
その結果は以下。
return do_post_token( body: TokenPostRequest = None )
期待しているモノと違う。operation.snake_case_arguments は、型ヒントやデフォルトパラメータまで含まれる様子。リクエストヘッダが付くと更に複雑になる。
return do_post_token( authorization: str = Header(..., alias='Authorization'), body: TokenPostRequest = None )
このままでは Syntax Error で動かなくなる。
jinja2の中で引数をパースする
素直に使うと失敗するので、変数名だけ抜き出してくる必要がある。単純に , で split すると、ヘッダの Header(..., が悪さをしてうまく拾えない。力業だけど以下の方法で回避する。
,で split してイテレーションする- 要素に
:が含まれるか調べ、無ければ次の要素に移る - 要素に
:が含まれるなら:で split して第一要素を変数名として扱う
実装するとこんな感じ。
return do_{{operation.function_name}}( {% for arg in operation.snake_case_arguments.split(',') %} {% if ':' in arg %} {{ arg.split(':')[0] }}={{ arg.split(':')[0] }}, {% endif %} {% endfor %} )
先の例だとこんな感じになる。
return do_get_token(
authorization=authorization,
body=body,
)
実体を作成する
後は、処理ルーチンの実体を実装する。例えば handler.py として以下のように用意する。
from models import * def do_get_token (**kwargs): return TokenPostResponse( token = 'XXXX' )
上記の例では、手抜のために可変長引数をつかっている。もちろん、下記のように真面目に書いてもいい。
from models import * def do_get_token (authorization, body): return TokenPostResponse( token = 'XXXX' )
そしてこれを import するコードをテンプレートの冒頭に追記する。
from handler import *
この from~ と同じように、DBアクセスなどのグローバルなコードがあるのなら、テンプレートの任意の箇所に直接 Python コードを記述する。
検証
検証環境
テンプレート
templ/main.jinja2 を以下のように作成。殆どは、デフォルトのテンプレートのまま。
from __future__ import annotations from fastapi import FastAPI {{imports}} from handler import * app = FastAPI( {% if info %} {% for key,value in info.items() %} {{ key }} = {{ value }}, {% endfor %} {% endif %} ) {% for operation in operations %} @app.{{operation.type}}('{{operation.snake_case_path}}', response_model={{operation.response}}) def {{operation.function_name}}({{operation.snake_case_arguments}}) -> {{operation.response}}: {%- if operation.summary %} """ {{ operation.summary }} """ {%- endif %} return do_{{operation.function_name}}( {% for arg in operation.snake_case_arguments.split(',') %} {% if ':' in arg %} {{ arg.split(':')[0] }}={{ arg.split(':')[0] }}, {% endif %} {% endfor %} ) {% endfor %}
----- 2021/12/13 21:50 追記 -----
ドキュメントページのサンプルにあるものをそのまま使うと、AttributeError が起こる。理由は FastAPI コンストラクタを定義する以下の箇所。
{{ key }} = "{{ value }}",
テンプレート指定なしでコードを生成すると、この value はリストとなるところらしく " で囲って str にしてしまうと処理に失敗する。なので、以下が正しい。
{{ key }} = {{ value }},
----- 追記終わり -----
----- 2023/09/13 21:50 追記 -----
上記の場合、title や description に多バイト文字がある場合などで SyntaxError などが生じる場合がある。文字列は " 囲うために以下とする方がよい。
{% for key,value in info.items() %}
{% if value is string %}
{{ key }} = "{{ value }},"
{% else %}
{{ key }} = {{ value }},
{% endif %}
{% endfor %}
----- 追記終わり -----
処理の実態を記述した外部ファイル
from models import * def do_get_token (**kwargs): return TokenPostResponse(token = 'XXXX' )
コードを生成
$ fastapi-codegen -t ./templ -i <OpenAPI Spec> -o .
生成されたコード
main.py
from __future__ import annotations from typing import Optional, Union from fastapi import FastAPI, Header from handler import * from .models import TokenPostRequest, TokenPostResponse app = FastAPI( ...(省略)... ) @app.post('/token', response_model=TokenPostResponse) def get_token(body: TokenPostRequest = None) -> TokenPostResponse: """ トークンの取得 """ return do_get_token( body=body, )
models.py
from __future__ import annotations from typing import Optional from pydantic import BaseModel, Field class TokenPostRequest(BaseModel): name: str = Field(..., description='username') key: str = Field(..., description='password') class TokenPostResponse(BaseModel): token: str = Field(..., description='token')
動作確認
Gunicorn/Uvicorn で動かして、curl で叩いてみる。
$ curl -s -X POST http://localhost:8000/token
{"token":"XXXX"}
うん。とりあえず動いている感じ。
FastAPI と Uvicorn で REST API 対応のスクリプトを簡単に動かす
 https://fastapi.tiangolo.comより
https://fastapi.tiangolo.comより
API監視による快適生活
以前、Zabbix で某ワクチン接種サイトの更新を拾って、Slack で飛ばす環境を構築した。
その後、この環境を育てていって、今は株価や天気を世の中の公開APIから拾って、Slackへ通知する仕組みを確立したのだけど、ふと私生活の情報をAPI化すればもっと捗るのでは無いかと思いついた。
ZabbixでAPIの監視ができると知ってから、株価や天気などを監視させてるんだけど、財布の残高とか、洗濯物のたまり具合とか、プライベートな情報をAPI化すれば、より捗る気がしてきた。
— kWatanabe (@WWatchin) 2021年12月4日
クラウドは維持費かかるし、ローカルでAPIを作る方法を調べてみるか。Dockerでもいいけど、まずは手作業で。
調べてみたところ、FastAPI という素敵なWebフレームワークがあって、これを使うと Python でちょっとしたスクリプトを書く感覚で API が作れると分かったので、試してみることにした。
検証
検証環境
単純に動かす
APIアプリに特化したPythonフレームワークのFastAPIを導入する。 また、FastAPI で推奨となっている ASGI 対応 AP サーバの uvicornを併せて導入する。
$ sudo apt install python3 python3-fastapi uvicorn python3-uvloop python3-httptools
ちなみに Debian 10 以前では FastAPI は apt で提供されていないので pip で導入する。
$ sudo python3 -m pip install fastapi
任意の場所にサンプルコードを設置。仮に、/srv/uvicorn とする。
$ sudo mkdir -p /srv/uvicorn $ sudo vim /srv/uvicorn/main.py
内容はシンプルに、/ を GET すると Hello, World. が JSON で返ってくる API を作る。
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return { "Hello": "World" }
試運転。
$ cd /srv/uvicorn $ uvicorn main:app --host 0.0.0.0 --port 8000
アクセスしてみる。
$ curl http://localhost:8000/
{"Hello":"World"}
以上おわり、楽チン過ぎる。
Uvicorn を Gunicorn のワーカーとして動かす
Uvicorn のドキュメントによると、 WSGI 対応 AP サーバの Gunicorn のワーカーとして動かすことが推奨されているので、Uvicorn を Gunicorn 配下で動くように変更する。
まず、Gunicorn を入れる。
$ sudo apt insatll gunicorn
なお、Debian 10 以前では、Python2 バージョンが入ってしまうので以下のようにする。
$ sudo apt install gunicorn3
Gunicorn と Uvicorn を連携させて、再度試運転。
$ cd /srv/uvicorn $ gunicorn main:app --workers 4 --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0:8000
アクセスしてみる。
$ curl http://localhost:8000/
{"Hello":"World"}
いやっほー!
リバースプロキシ配下に置く
実運用では AP サーバ 単体を露出させることは無いだろうし、SSL の終端なども必要だろうということで、リバースプロキシとして nginx をかませる。 静的コンテンツとの区別やAPIバージョンごとにAPサーバを分けたい場合などのため、/api/v1 プレフィックスがついているものは Gunicorn へ飛ばすようにする。
nginx を入れる。
$ sudo apt install nginx
nginx.conf の server ディレクティブに以下を追記する。
...
location ^~ /api/v1/ {
proxy_pass http://GunicornサーバのIPアドレス:8000;
}
...
アプリで FastAPI クラスを作成する際にプレフィックスを指定する。
... app = FastAPI( root_path = "/api/v1/" ) ...
nginx につないでみる。
$ curl http://nginxのIPアドレス/api/v1/
{"Hello":"World"}
完璧すぎる。
CORS に対応させる
調子に乗って、もう一歩。今回のように Zabbix から監視したい程度ならともかく、普通はAPIを素で使うことはあまりないだろうし、大概は何らかのフロントエンドアプリと疎通することになると思うので、CORS へ対処する必要がある。
FastAPI では、オリジンとして許可するドメインを FastAPI() クラスに与えることで解決できる。こんな感じ。
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI( root_path = "/api/v1/" )
origins = [
"http://excample.com",
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.get("/")
def read_root():
return { "Hello": "World" }
おわりに
これで FastAPI を使って API アプリを作るための殻ができあがった。あとは好きに API を実装すればいい。
URIとHTTPメソッドによるルーティングはデコレータ (@app.get("/"))、リクエストボディのバリデーションは型ヒント、レスポンスはディクショナリを渡してあげれば (return { "Hello": "World" })、面倒な HTTP 通信やJSONのパースなどは全部やってくれる。
KVMでTPMをエミュレートしてWindows11を動かす
KVM (Proxmox VE) で TPM 2.0 をエミュレートする環境を構築した- KVM (Proxmox VE) で TPM 2.0 をエミュレートしたVMを作り、Windows11を動かしてみた
Windows11のシステム要件
先日、Windows11がリリースされたが、その動作条件の厳しさに一部で話題になっている。
上記の Microsoft のWebサイトから一部引用すると以下の通り。
| 項目 | 要件 |
|---|---|
| CPU | 1GHz で 2コア以上 Intel なら Coffee Lake 以降 AMD なら Zen+ 以降 |
| RAM | 4GB 以上 |
| Storage | 64GB 以上 |
| Firmware | UEFI / Secureboot 対応 |
| TPM | 2.0 以降 |
CPUの世代は、KabyLake も Zen も 5年前 のものだし、Windows10も継続提供されるので、「新しいOSを使いたければ、新しいマシンを使ってください」という主張はまぁ良しとする。(なんだかんだで動くでしょうし)
ただ、TPM が必須となっている点はちょっと気になるところ。VMでTPMのエミュレーションって、可能だったかな。
VMでのTPMエミュレーション
ざっと調べてみただけでも、イマドキのハイパーバイザでは vTPM のサポートに特に問題はなさそう。
QEMU/KVM
QEMU/KVM では、swtpm というモジュールで vTPM をサポートしている。
Hyper-V
Hyper-V では、Windows Server 2016 以降で vTPM をサポートしている。
VMware vSphere
VMware vSphere では、vSphere 6.7 以降で vTPM をサポートしている。
検証
QEMU/KVM ( Proxmox VE ) でvTPM をエミュレートできる環境を構築して、Windows11 を動かしてみる。
…つもりだったのだけれども、モタモタしていたら、先日の ProxmoxVE のアップデートで vTPM が標準でサポートされてしまった。哀しみ。
手順
元々やろうとしていたこと
本来は以下のような手順で vTPM 環境を構築するつもりだった。
# swtpm socket --tpmstate dir=/var/run/tpm --tpm2 --ctrl type=unixio,path=/var/run/tpm/sock
... -bios ビルドしたUEFIファーム -chardev socket,id=tpmc,path=/var/run/tpm/sock -tpmdev emulator,id=tpm,chardev=tpmc -device tpm-tis,tpmdev=tpm ...
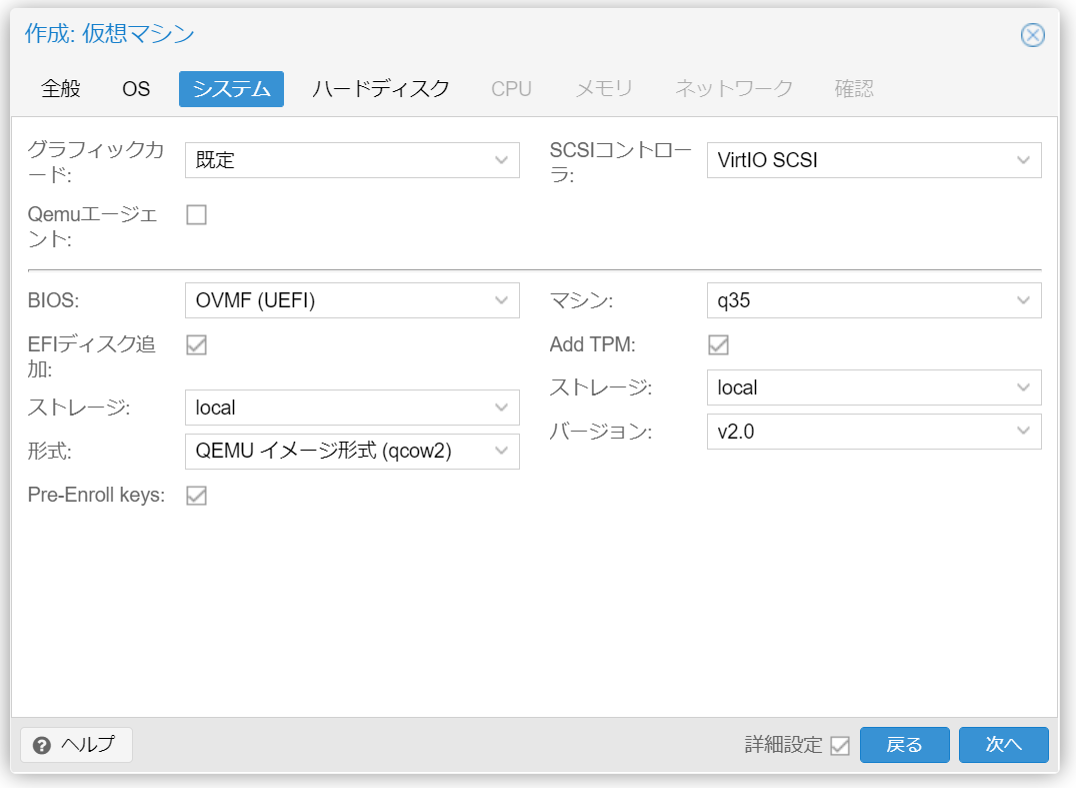
今やればいいこと
しかし、最近のProxmox VEのアップデートで、vTPMを追加するメニューが追加されたので、今ならここをポチーするだけで終了。ポコペン。
一応、注意点としては以下。
結果

とんだ肩透かしだったけど。まぁ、こんな感じ。
Pythonでブラウザで動く "ぷよぷよっぽいもの" を作る
- ブラウザ上で動く "ぷよぷよっぽいもの" をフルスクラッチで作った
- Brython というブラウザで動作する Python 処理系を用いて JavaScript を書かずに実装した
ぷよぷよeスポーツ×プログラミング
…という教材があるんです。殆ど読んでないんですが、曰く、以下のような代物のようです。
プログラミング学習環境『Monaca Education』において、セガが展開するアクションパズルゲーム『ぷよぷよ』をプログラミング学習できる教材です。 製品版と同じ画像素材を利用して、世界中で使われるコンピュータ言語を使い、プロが使う開発環境で本物のプログラミングをお楽しみください。
面白そうじゃないですか。やってみようと思い、著作物利用許諾書に目を通すと、以下の記述がありました。
本利用条件に基づき改変した本プログラム等の著作権(著作権法第21条から第28条までに定めるすべての権利を意味します)は、当社に無償にて譲渡及び移転するものとします。また、使用者は、当社が当該本プログラム等を、当社の判断で、商用であるか否かにかかわらず、いかなる方法にて、利用、公開、公表、販売もしくは頒布等を行うことができることを承諾するものとします。
https://puyo.sega.jp/program_2020/dl/puyo-programming-code.pdf より引用
この教材には、ソースコードに加え、画像ファイルなども含まれているようなので、改変した成果物を自由に扱える権利を与えるわけにはいかないのは分かるんですけど。その成果物の権利を逆に召し上げるっていうのはどうなんだ。
なんとなく、ムッとしたので、この教材に頼らずに、「ぷよぷよっぽい何か」を独力で作ってみようと思いました。
教材に頼らず独力で作る
どうやって作るか?
kWatanabe の知るブラウザのプラットフォームと言えば Flash でした。今は HTML5 か。
ただ、kWatanabe は Low-Level な開発を生業にしており、扱える高級言語は Python くらいです。ブラウザで走る Python の処理系を探しました。
Brython という JavaScript で実装された Python 処理系です。ライセンスは 3条項BSD。
brython.js と brython_stdlib.js という js ファイルをロードして、<canvas> や <div> で描画領域を用意してあげれば、あとはインラインで Python コードを生で書いていくことができます。
例えば以下のような感じでしょうか。
<!DOCTYPE html> <html> <head> <title>Brythonサンプル</title> <meta charset="utf-8"> <script type="text/javascript" src="brython.js"></script> <script type="text/javascript" src="brython_stdlib.js"></script> </head> <body onload="brython()"> <canvas id="drawarea" width="192" height="384" style="border: 1px solid black;"></canvas> ... 描画先となる HTML5 のオブジェクトを定義する。 ... <script type="text/python"> from browser import document from browser import html ... Python コードを記述する。 ... </script> </body> </html>
JavaScript と同様、HTMLファイルにソースコードを記述していく*1ので、中身はモロバレです。隠したいなら難読化などの、工夫が必要です。
あと、brython_stdlib.js に実装されていないモジュールは使えません。なので、Python 標準のモジュール以外は基本的に使用できないですが、それでも処理系としては JavaScript と比べてかなり協力です。
kWatanabe のように JavaScript をよく知らない人間や、 JavaScript にアレルギーを持つような人には、選択肢のひとつになるんじゃないでしょうか。
成果物
プレビュー
とりあえず、こんな感じになりました。連鎖で石を消すときの処理が何か怪しい?かも。

デモ
近日中に、期間限定でデモを置く予定です。
操作は以下のとおりです。
| キー | 効果 |
|---|---|
| W | ゲームの開始 |
| A | 石を左に動かす |
| S | 押し続けている間、落下速度が増す |
| D | 石を右に動かす |
| スペース | 石を回転させる |
ソースコード
GitHubで公開します。ライセンスは GPL Version.2 です。
所感
- JavaScript を一切書かなくても、ブラウザのフロントエンドやアプリを作れる方法があることを知った
- とはいえ、処理系のために数MBの js をロードさせるのは、ユーザフレンドリーではなさそうなので、使いどころは選ぶかも
*1:srcタグでロードすることもできますが、そのファイルを直接開かれると結局同じ。
Zabbixで任意のWebサイトの更新を監視する
- ZabbixのHTTPエージェントで、Webサイトの更新を監視させる
- 更新があれば、Slack で通知を投げて貰い、日々のWebサイトの巡回を省力化する
日々のWebサイト巡礼を機械に任せたい
デジタル世界にどっぷり浸かった kWatanabe は、株価情報とか、某ワクチンの予約サイトとか、いくつかのWebサイトの更新を日々確認している。毎日更新されるものなら良いけども、立会外分売の情報のようにそうとは限らないものも多い。
意味の無いルーチンワークはできるだけ機械に任せてしまい、人間様はもっと実になることに時間を使いたい。
Zabbix にWebサイトを監視させる
Zabbix はシステム監視ツールのひとつで、サーバやサービスの負荷状況や障害、その兆候となる事象を監視し、その結果を通知できる。
Zabbix 3.x 以前は、サーバ本体やネットワークなどの機材の監視が主な機能だったが、Zabbix 4.0 以降ではシステムのクラウド化・API化に伴い、監視も通知も Web サービスを意識したものが実装されている。
この中での「HTTPエージェント」と「Slack通知」を使って、手軽にWebサイトの監視システムを構築できる*1。
検証
ここでは、最もシンプルに「何でもいいのでWebサイトが更新されていたら Slack へ通知」する場合を考える*2。対象は、現在、日本でホットなWebサイトと思われる自衛隊の某ワクチン接種に関するサイトを監視してみる。
検証環境
Zabbixのインストール・Slackアカウントの作成は割愛。
Slack にアクセスするための権限を設定
Slack のアカウントから、ディベロッパー用サイトにアクセスする。
「Create New App」→「From Scratch」を押下し、アプリの名称と連携させるSlack Workspaceを選択する。
アプリが作成されたら、「アプリ名」→「Basic Information」→「Add features and functionality」を押下して、Bots を選択する。
「OAuth & Permissions」→「Scopes」→「Add an Oauth Scope」を押下して、chat: write を追加する。その後、「OAuth Tokens for Your Workspace」の「Bot User OAuth Token」の「Copy」を押下し、テキトーなファイルに貼り付けておく。
Slack に通知用チャンネルを作成
Slack にログインし、Zabbix からの通知を受け取るためのチャンネルを作成する。名前は必ず英数字のみにする。
その後、チャンネルを右クリック「チャンネル詳細を開く」→「インテグレーション」→「App」→「アプリを追加する」を押下して、作成したアプリを登録する。
Slack 通知の設定
Zabbix の画面で「管理」→「メディアタイプ」→「Slack」→一番下の「複製」を押下し、以下を入力する。
- 名前:Slack以外の任意の名前(ここでは、
Slack (Simple)) - bot_token:Slackからコピーした「Bot User OAuth Token」の値
- event_opdata:適当な文字列
- 本来は、取得したデータを挿入するマクロが登録されているが、64KBを超えるとSlackへの投稿に失敗するため、テキトーな値に置き換えておく。
問題なければ「追加」を押下する。
登録されたメディアの右端にある「テスト」リンクを押下し、以下を入力した後に「テスト」ボタンを押下する。
- channel:追加したSlackチャンネル名
- event_id:1
- event_source:1
- zabbix_url:ZabbixのトップページのURL
ここまでの設定が問題なければ、Slack経由でテスト通知が送られてくるはず。


テストで問題なければ、「管理」→「ユーザ」→利用しているZabbixユーザ→「メディア」で以下を入力し、「追加」を押下する。
- タイプ:追加したメディア(ここでは、
Slack (Simple)) - 送信先:追加したSlackチャンネル名
Webサイトの監視の設定
Zabbixの画面から、「設定」→「ホスト」→「Zabbix server」→「アイテム」→「アイテムの作成」を選択。
以下のパラメータを入力する。
- 名前:わかりやすい任意の名前(ここでは、
自衛隊ワクチン更新) - タイプ:HTTPエージェント
- キー:わかりやすい英数字の名前(ここでは、
jgsdf_vaccine) - URL:監視対象のWebページのアドレス
- 監視間隔:情報を点検する時間間隔(ここでは、
30m)- 人力で行ったとしても不自然ではない程度にする。
- 高頻度での監視は、BANされる可能性もある。また、「前回の監視結果から変化があった」ことを判断基準とするため、短く設定しすぎるとすぐ「解決」状態になってしまい、訳が分からなくなる。
- データ型:テキスト
- ヒストリの保存期間:14d
- 有効:チェックする

設定できたら、「テスト」→「値の取得とテスト」を押下して、「結果」欄にWebサイトのソースが表示されることを確認する。問題なければ「キャンセル」した後、「監視データ取得」と「追加」を押下する。
監視と通知を紐付ける設定
Zabbixの画面から、「設定」→「ホスト」→「Zabbix server」→「トリガー」→「トリガーの作成」を選択。
以下のパラメータを入力し、「追加」を押下する。
- 名前:わかりやすい任意の名前(ここでは、
自衛隊ワクチン更新) - 深刻度:
情報 - 条件式:「追加」ボタンを押下して、以下を入力
- アイテム:作成したアイテム(ここでは、
Zabbix server: 自衛隊ワクチン更新) - 関数:
change() - 最新値と前回値との差分 - 結果:
<>と0
- アイテム:作成したアイテム(ここでは、
再び、「設定」→「ホスト」→「Zabbix server」→「アイテム」を選択し、作成したアイテムを探し、「トリガー」にトリガー1が表示されており、クリックすると作成したトリガーが表示されることを確認する。

最後に、Zabbixの画面から、「設定」→「アクション」→「トリガーアクション」→「アクションの作成」を押下して、以下を入力し、「追加」を押下する。
- 「アクション」タブ
- 名前:わかりやすい任意の名前(ここでは、
Report problems to Slack (Simple)) - 計算のタイプ:
Or - 実行条件の「追加」を押下して以下を入力
- タイプ:
トリガー - オペレータ:
等しい - トリガー:作成したトリガー(ここでは、
Zabbix server: 自衛隊ワクチン更新)
- タイプ:
- 有効:チェックする
- 名前:わかりやすい任意の名前(ここでは、
- 「実行内容」タブ
- 実行内容の「追加」を押下して以下を入力
- ユーザに送信:Slack通知の設定で登録したZabbixユーザ
- 次のメディアのみ使用:追加したメディア(ここでは、
Slack (Simple))
- 実行内容の「追加」を押下して以下を入力
結果
上記の設定が全て完了していれば、Webページの更新されると以下のような通知が Slack にやってくる。

これで、人間様はWebサイトに貼りつきになって無駄な時間を浪費することなく、もっと実のあるステキな時間をすごすことができるようになる。
なお、本ブログは全体を通じて無保証です!